背景介绍
文本情感分析是在文本分析领域的典型任务,实用价值很高。本模型是第一个上手实现的深度学习模型,目的是对深度学习做一个初步的了解,并入门深度学习在文本分析领域的应用。在进行模型的上手实现之前,已学习了吴恩达的机器学习和深度学习的课程,对理论有了一定的了解,感觉需要来动手实现一下了。github对应网址https://github.com/ble55ing/LSTM-Sentiment_analysis
LSTM(Long Short-Term Memory)是长短期记忆网络,在自然语言处理的领域有着较好的效果。因此本文使用LSTM网络来帮助进行文本情感分析。本文将从分词、向量化和模型训练三个方面对所训练的模型进行讲解,本文所实现的模型达到了在测试集99%的准确率。
中文文本分词
首先需要得到两个文档,即积极情感的文本和消极情感的文本,作为训练用到的数据集,积极和消极的各8000条左右。然后程序在载入了这两个文本的内容后,需要进行一部分的预处理,而预处理部分中最关键的就是分词。
分词 or 分字
一般在中文文本的分词处理上,最常使用的就是jieba分词,因此在一开始训练模型的时候,也是使用的jieba分词。但后来感觉效果并不太好,最好的时候准确率也就达到92%,而且存在较为严重的过拟合问题(同时测试集准确率达到99%)。因此去和搞过一段时间的自然语言处理的大佬讨论了一下,大佬给出的建议是直接分字,因为所收集的训练集还是相对来说少了一点,分词完会导致训练集缩小,再进行embedding(数据降维)之后词表更小了,就不太方便获取文本间的内在联系。
因而最后分词时比较了直接分字和jieba分词的效果,最终相比之下还是直接分字的效果会更好一些(大佬就是大佬),所以选用了直接分字。直接分字的思路是将中文单字分为一个字,英文单词分为一个字。这里需要考虑到utf-8编码,从而正确的对文本进行分字。
去停用词
停用词:一些在文本中相对来说对语义的影响不明显的词,在分词的同时可以将这些停用词去掉,使得文本分类的效果更好。但同样的由于采集到的样本比较小的原因,在进行了尝试之后还是没有使用去停用词。因为虽然对语义的影响不大,但还是存在着一些情感在里头,这部分信息也有一定的意义。
utf-8编码的格式
utf-8的编码格式为:
如果该字符占用一个字节,那么第一个位为0。
如果该字符占用n个字节(4>=n>1),那么第一个字节的前n位为1,第n+1位为0。
也就是不会出现第一个字符的第一个字节为1,第二个字节为0的情况。
实现
#将中文分成一个一个的字
def onecut(doc):
#print len(doc),ord(doc[0])
#print doc[0]+doc[1]+doc[2]
ret = [];
i=0
while i < len(doc):
c=""
#utf-8的编码格式,小于128的为1个字符,n个字符的化第一个字符的前n+1个字符是1110
#print i,ord(doc[i])
if ord(doc[i])>=128 and ord(doc[i])<192:
print ord(doc[i])
assert 1==0#所以其实这里是不应该到达的
c = doc[i]+doc[i+1];
i=i+2
ret.append(c)
elif ord(doc[i])>=192 and ord(doc[i])<224:
c = doc[i] + doc[i + 1];
i = i + 2
ret.append(c)
elif ord(doc[i])>=224 and ord(doc[i])<240:
c = doc[i] + doc[i + 1] + doc[i + 2];
i = i + 3
ret.append(c)
elif ord(doc[i])>=240 and ord(doc[i])<248:
c = doc[i] + doc[i + 1] + doc[i + 2]+doc[i + 3];
i = i + 4
ret.append(c)
else :
assert ord(doc[i])<128
while ord(doc[i])<128:
c+=doc[i]
i+=1
if (i==len(doc)) :
break
if doc[i] is " ":
break;
elif doc[i] is ".":
break;
elif doc[i] is ";":
break;
ret.append(c)
return ret
文本向量化
接下来是需要对分完字的文本进行向量化,这里使用到了word2Vec,一款文本向量化的常用工具。主要就是解决将语言文本处理成紧凑的向量。简单的文本转化往往是相当稀疏的矩阵,即One-Hot编码。转换的文本向量就是把文本中所含的词的编号的位置置为1.这样的编码方式显然是不适合进行深度学习模型训练的,因为数据过于离散了。因此,需要将向量维数进行缩减。word2Vec就能够较好的解决这个问题。
Word2Vec
Word2Vec能够将文本生成相对紧凑的向量,这个过程称为词嵌入(embedding),其本身也是一个神经网络模型。训练完成之后,就能够得到每个词所对应的低维向量了。使用这个低维向量来进行训练,能够达到较好的训练效果。
实现
def word2vec_train(X_Vec):
model_word = Word2Vec(size=voc_dim,
min_count=min_out,
window=window_size,
workers=cpu_count,
iter=5)
model_word.build_vocab(X_Vec)
model_word.train(X_Vec, total_examples=model_word.corpus_count, epochs=model_word.iter)
model_word.save('../model/Word2vec_model.pkl')
input_dim = len(model_word.wv.vocab.keys()) + 1 #下标0空出来给不够10的字
embedding_weights = np.zeros((input_dim, voc_dim))
w2dic={}
for i in range(len(model_word.wv.vocab.keys())):
embedding_weights[i+1, :] = model_word [model_word.wv.vocab.keys()[i]]
w2dic[model_word.wv.vocab.keys()[i]]=i+1
return input_dim,embedding_weights,w2dic
模型训练
激活函数
LSTM模型的训练,其激活函数选用了Softsign,是一个对于LSTM来说的时候比tanh更加合适的激活函数。
模型层数
在全连接层数的选取上,本来是使用了一层的全连接层,0.5的dropout,但在一开始的分词方式下,产生了较为严重的过拟合情况,因此就尝试着再添加一层Relu的全连接层,0.5的dropout,效果是确实可以解决过拟合的问题,但并没有提升准确率。因此就还是回到了一层全连接层的状况。相比之下,一层比两层的训练逼近速度快得多。
损失函数
损失函数的选取:这一部分尝试了三个损失函数,mse,hinge和binary_crossentropy,最终选用了binary_crossentropy。
mse这个损失函数相对普通,hingo和binary_crossentropy是较为专用于二分类问题的,而binary_crossentropy还往往与sigmoid作为激活函数一同使用。也可能是在使用hinge的时候没有用对激活函数吧。
评估标准
一开始的时候,评估标准定的是只有准确率(acc),然后准确率一直上不去。后来添加了平均绝对误差(mae,mean_absolute_error),准确率一下子就上去了,很有意思。
总结
总的来说,自己搭模型调参的过程还是很必要的一个过程,内心很煎熬,没有自动调参的工具吗。。能够调出一个效果不错的模型还是很开心的。感觉在深度学习这块还是有很多的经验在里面,是需要花些时间的。
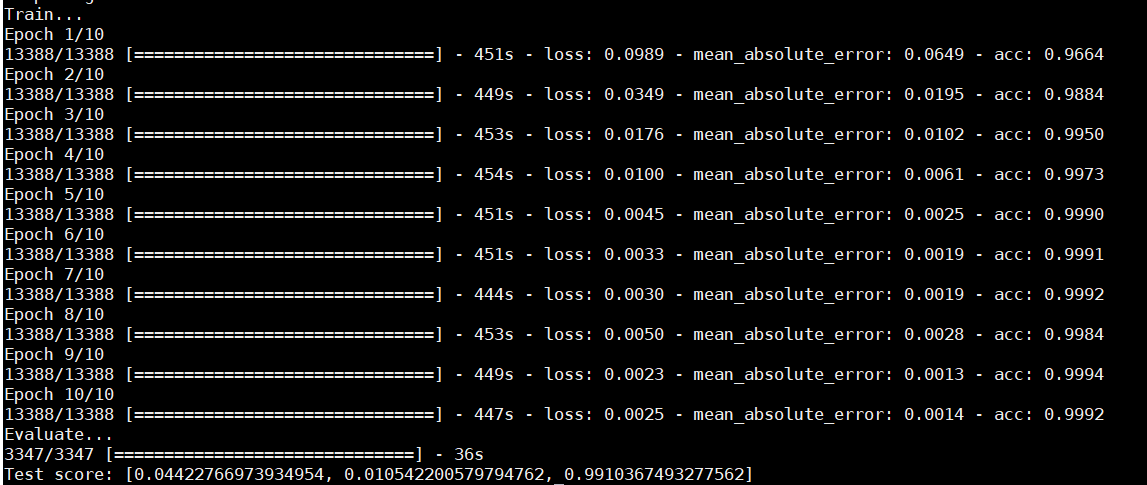
附上结果图一张。