格式自适应技术研究
本文提出了一种基于自由度评估值的样本格式自适应技术,能够较好的区分强格式约束,弱格式约束和非格式定义,对组关联格式不能起到较好的效果。
论文关注的研究现状
现有灰盒测试技术的样本变异策略包括比特反转、字节反转、整数加减、已知整数覆盖、复合变异和样例拼接等。通过变异可以大幅扩充样本的数量,以保证灰盒模糊测试的持续进行
论文的主要工作
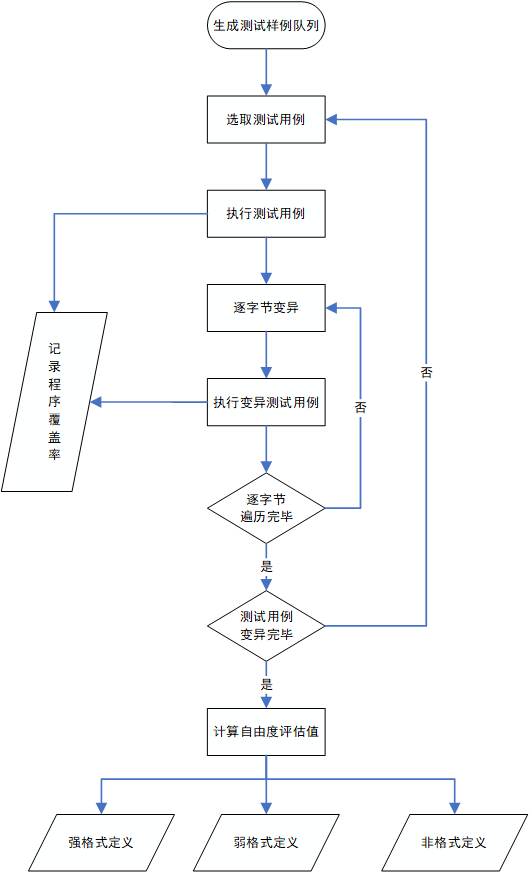
将样本格式根据格式要求分为四类
强格式定义:即魔术字,这些个字段往往往往会造成输入样本在格式判断的浅层分支就被抛弃,直接导致该样本无法进入测试目标的深层分支,不能对模糊测试的整体进程产生有效作用。
弱格式定义:属于该定义部分数据的变异需要控制在一定的范围内的随机,该范围是确保满足该定义的输入样本可以大概率影响到测试目标的深层分支。
组关联格式定义:满足该定义的数据同组之间具有关联性,如果改变同组中某部分的数据,势必会造成因为校验错误等问题导致整体无法通过格式检查。
非格式定义部分。该定义下的数据部分没有特殊格式要求,对该部分数据变异的自由度最高,是扩充输入样本库的关键。
技术实现方案
此方法采用单字节变换输入的方式来检查样本每一字节的种类。需要维持一个表示覆盖率信息的数组cover_rate[i][j],其中的下标i为样本的长度,0<=i<=len(sample),下标j为样本变异出来的样本编号0<=j<=Nchange。Nchange为变异此字节产的样本个数。
接下来对该测试样例进行无规则的随机变异,每次仅变异一个字节,并将变异获得的样本作为输入执行测试目标,获得该测试样例每一字节对应的多组变异样本执行的分支覆盖率,将该样例变异获得的样本作为输入执行测试目标产生的分支覆盖率汇总到二维数组cover_rate当中。
然后需要求出变异样本对应执行的代码覆盖率与原始样例对应执行的代码覆盖率的比值rate,然后根据得到的这些每一位变异得到的样本的比值,算出每一位的rate的均值和标准差,使用均值和标准差的乘积来的作为这一位的评估值。如果自由度评估值小于阈值T1,则将该字节定义为强格式定义数据;如果该值大于阈值T1且小于阈值T2,则将该字节定义为弱格式定义数据;如果该值大于阈值T2,则将该字节定义为非格式定义部分。组关联的格式定义无法通过这种方式来确定