Welcome to ble55ing's blog
blessing the world-
ISC2019 笔记
ISC2019 笔记
ISC2019,在雁栖湖开的,赶上下雨了,有点尴尬。
上午主要听了工控的分享,下午听了漏洞挖掘与运用的分享。
总得来讲感觉ISC作为企业间合作的平台的意味更浓一些。
据说会分享PPT,但也没看到获得的通道,过两天看看公众号吧。
万物互联的智慧城市
一开始参加的是这个,设想很有意思,要让普通市民找到汇报的窗口,比如哪哪有医托,哪哪有黄牛,能够及时的通报到大数据平台,然后能够汇总到城市模型。(然后是交给公安?还是开放给大众?是个问题)。
工控安全之花落知多少
从5个方面分析了工控安全的缺陷产生途径,很有启发性,还是等等PPT吧
Blue Keep 远程利用 扫描与防护
CVE-2019-0708
这是一个关于MS_T120的漏洞,这个链接时并没有进行引用计数,因此即使关闭了原连接,之后伪造的数据还是会被处理,就构成了一个UAF。
关于Windows下通常的UAF利用方法:使用堆喷的方式去找到这个块,堆喷可以导致任意地址写,(如x86的int 0x2e?,这个可能是类似int 0x80的东西,需要查一下)
Win10 RS1之后添加了页表随机化,就不能当做固定地址了,而之前的都是固定位置,就可以当做任意地址写的目标。
存在信息泄露 -> 任意地址call
不存在信息泄露-> 任意地址写改页表再任意地址call。
即时通信软件如FaceTime,Whatsapp
1 发的包包含uuid,回来的包也包含相同的uuid,而在处理中没有做初始化,会按照16字节做处理,所以应该会包含栈中信息。
本地测试成功,但实际发现苹果服务器中如果uuid不足16位就会返回一串奇奇怪怪的uuid,不包含原uuid。
2 苹果的stack canery实现机制存在问题,12.04之前的版本中stack canery的位置是错误的,方向反了不能防止overflow,这很有可能是llvm编译器的问题。
Unix Socket domain漏洞
有一些有锁的行为会由于某些原因在一定情况下打开锁,而这时可能会触发条件竞争、UAF等、
-
de1ctf Mine sweeping
de1ctf的Mine sweeping
勇气、危机、未知、热血、谋略,3A级游戏大作——扫雷
题目分析
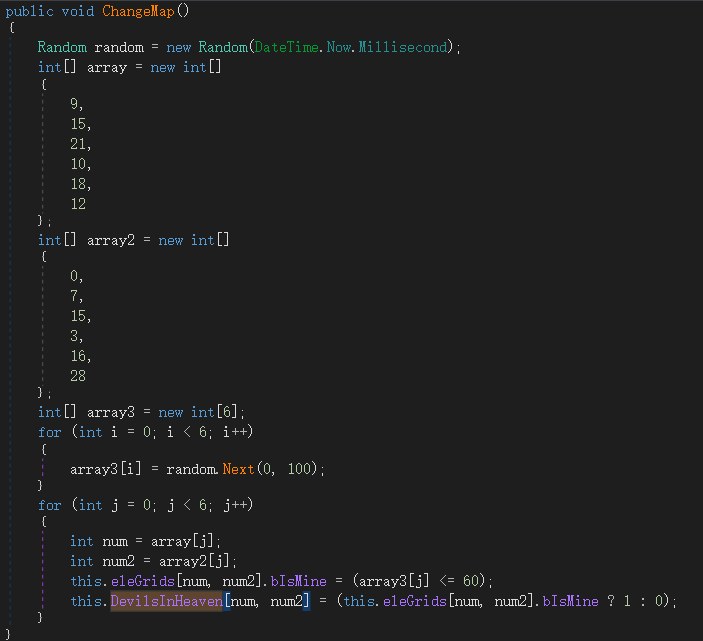
题目是一个Unity游戏,将其Assembly-CSharp.dll放到dnSpy里,看到其地图分析的逻辑。找到其地图相关的信息。

找到了一个DevilsInHeaven数组,但这个数组并不是按照顺序来的,其中的每一个数据,是从下往上的某一列的数据,1为有雷,0为没有。
然后还找到了Changemap的函数,该函数说明了这个雷的分布也不是完全和前面那个数组一样的,有一些位置(6个)被进行了随机。
得到二维码
这个扫雷雷太多了,所以是不可能正常的扫出来的。
由于ChangeMap改的非常少,所以每次的图其实差别不大。
发现了左上左下和右下的大方框和右上的小方框,感觉是向左旋转90度的二维码。
然后一列一列试DevilsInHeaven数组中的数据,找到对应的列
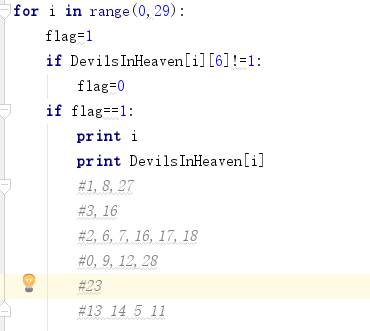
编了个小程序去找合适的列,有的列的前几位这中有被修改了部分,比如最后一列,就没有在这里显示出来。

整理出来就是这样的一个二维码,其中灰色的框为随机数的,这里有5个,最后一个在左下的最后一行里,由于是大方框的一部分就没有标出来。
扫描二维码得网址得flag
-
使用Vultr搭建VPS
使用Vultr搭建VPS
国际赛没有VPS网卡的真的是。。所以还是要搭一个
Vultr
一个卖服务器的网站,:http://www.vultr.com,目前支持支付宝和微信了
服务器纽约的有优惠,但2.5美元的只支持ipv6,也有3.5美元的,其他地区最便宜5美元
看网上的文章建议centos 6 x64
建完服务器可以在Products里看到,并在detail里面做设置,这里有IP和password
SSR
用用户名和密码ssh上去,用户是默认root。
登上去首先是配置SSR,
apt install yum yum -y install wget wget --no-check-certificate https://freed.ga/github/shadowsocksR.sh; bash shadowsocksR.sh然后根据提示输入密码和端口
然后部署Google的BBR拥塞控制算法
wget --no-check-certificate https://github.com/teddysun/across/raw/master/bbr.sh chmod +x bbr.sh ./bbr.sh然后就可以使用SSR的客户端去设置代理了。
SSR客户端需要NET Framework 4.5.2以上,下载链接:
https://dotnet.microsoft.com/download/thank-you/net472
端口更新
如果想要换个端口,则可以通过修改/etc/shadowsocks.json 的方式,修改完之后重启SSr服务器即可
service shadowsocks restart
###参考资料
-
python 2.7到3.7的升级之路
python 2.7到3.7的升级之路
2020年1月1日起,python2.7就停止维护了。虽然是好多功能和库并没有完全支持python3的今天,也还是来学习一下如何将python2.7修改为python3的程序
运行环境
python 3的安装包先在官网https://www.python.org/downloads/下载了,然后安装。安装时注意一下选项,改一下安装位置,把环境变量啥的添上。然后将其安装目录下的python.exe更名为python3.exe,就可以用了。
使用的编译器是pycharm,在file->setting里换编译器。
然后更新一下pip,毕竟之后要安装库的
python2 -m pip install --upgrade pip --force-reinstall python3 -m pip install --upgrade pip --force-reinstall之后要安装什么库的时候,python -m pip install xxx或者python3 -m pip install xxx,感觉比pip3稳定(也可能是我pip3太久没更新了),所有库python3和python2都是要分开装的
语法变更
print 要加括号,exec也是
raw_input()直接写input()
本来的raw_input能够进行格式的预测,如默认int,有小数点是float,有引号是str,input默认全为str
数字全部为float型
python2中,整数相除为整数,python3中,是真正的除法,全为float型,想达到python2中的
/的效果,可以用\\。新的报错
编码格式
报错,UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0xa2 in position 49: illegal multibyte sequence,需要更改为fr = open(file_path,’r’,encoding=’UTF-8’)
map使用
TypeError: ‘map’ object is not subscriptable 和TypeError: object of type ‘map’ has no len()
解决方法还是list(map())的方法
参考资料
-
如何提升代码的可读性(+)--以python为例
如何提升代码的可读性(+)–以python为例
最近总是遇到不得不编程的情况,为了能够写出不会让几个月后的自己看不懂的代码,决定开始写这篇文章,来记录一下编程心得。
将语句简单化:lambda的使用
使用lambda语句,将多行语句精简为1行,提升代码可读性。
lambda是一个精简的匿名函数,其后跟的是参数,冒号后面跟返回值。
#下列语句可以将CODE字典进行翻转 UNCODE = dict(map(lambda t:(t[1],t[0]),CODE.items()))全局变量不要设置过多
全局变量一般是影响整个程序的关键变量,如果一个变量从头用到尾,可以尝试设置为全局,否则最好设置为局部变量,如果实在不方便的,也可通过文件存储的方式进行变量传输。
因为全局变量使用时还要声明global,如果出错的话后期需要修改,如果是全局变量修改起来的工程量相对更大,会使得代码维护困难。
库函数/迭代器的使用
Counter 计数器
使用方法如下所示
import collections counter = collections.Counter(['11','22','33','11']) #也可以直接声明为Counter(11=2, 22=1,33=1) print(counter) # Counter({'11': 1, '22': 1, '33': 1}) #获取其中数据的方法 print(list(counter.elements()))#根据元素计数重排的list['11', '11', '22', '33'],elememts返回的是一个迭代器 print(counter.items())#item返回一个dict_items类型dict_items([('11', 2), ('22', 1), ('33', 1)]) for k,v in counter.items():#获取dict_items中的数据 print(k,v)注意:counter中的数并不一定是正数和0,也可以通过减操作变成负数,但两个counter相减只会保存正数计数的元素。
yield 迭代器
类似于return,可以用来当函数的返回值使用,其与return的区别在下面说明:
def func(): print("func start") i=0 while True: yield 0 i+=1 print("res:",i) res = func() print("A =====") print(next(res)) print("*****") print(next(res)) print(next(res)) #其运行结果为 A ===== func start 0 ***** res: 1 0 res: 2 0当res = func()时,函数并没有真正执行,而是首先返回一个生成器,而在此时函数func并没有执行,在第一次执行next函数的时候,这个函数才真正执行,然后执行到yield,就相当于return了。而函数就停留在yield执行之后的位置,next函数第二次执行时就继续yield之后的语句。
glob目录文件遍历
使用glob可以匹配目录下的所有文件名
import glob for name in glob.glob('dir/*'): print (name)使用集合进行列表去重
换成集合然后再转list
a = set(list1)
list1 = list(a)
GIL 全局解释器锁
同一进程中假如有多个线程运行,一个线程在运行python程序的时候会霸占python解释器(加了一把锁即GIL),使该进程内的其他线程无法运行,等该线程运行完后其他线程才能运行。如果线程运行过程中遇到耗时操作,则解释器锁解开,使其他线程运行。所以在多线程中,线程的运行仍是有先后顺序的,并不是同时进行。
多进程中因为每个进程都能被系统分配资源,相当于每个进程有了一个python解释器,所以多进程可以实现多个进程的同时运行,缺点是进程系统资源开销大
-
如何提升代码的复杂性(-)--以python为例
如何提升代码的复杂性(-)–以python为例
最近总是读一些别人写的源码,也有一些心得,在这篇里记录一下。
变量名的命名
变量名的命名会很大的程度的减少代码的可读性,比如下面的代码,将变量命名为ll(小写的L),然后再在后面使用这个变量的时候就会出现情况,当看到循环的时候,首先就会认为这是十一,然后影响对代码逻辑的分析。

这样的情况会出现比如l(小写的L)、I(大写的i)、和数字1的区别,O(大写的o)和数字0之类的。
不规范的函数返回值
python中也有很多种变量类型,将所有函数返回值或许多的数据结构都定义为str类型并使用字符串处理的方式编写程序也不是不行,但这样就会使得程序很复杂。
变量赋值、浅拷贝、深拷贝
pthon中的变量存储对于每个变量名都是类似于指针的方式,所以如果复制的方式不恰当很可能会导致对原数据一同进行了修改。来看下面的示例:
import copy list = [0,"000",[0,90,900]] listcopy1 = list listcopy2 = copy.copy(list) listcopy3 = copy.deepcopy(list) print(list) listcopy1[0] = 1 listcopy1[1]="111" listcopy1[2][0]=1 print(list,listcopy1) listcopy2[0] = 2 listcopy2[1]="222" listcopy2[2][0]=2 print(list,listcopy2) listcopy3[0] = 3 listcopy3[1]="333" listcopy3[2][0]=3 print(list,listcopy3) #结果 [0, '000', [0, 90, 900]] [1, '111', [1, 90, 900]] [1, '111', [1, 90, 900]] [1, '111', [2, 90, 900]] [2, '222', [2, 90, 900]] [1, '111', [2, 90, 900]] [3, '333', [3, 90, 900]]有一个叫做copy的库,可以用来做拷贝;可以看到直接赋值是指针赋值,只变了地址;copy()是浅拷贝,变量其中包含的变量还是指针;deepcopy()是深拷贝,完全一份新的。