Welcome to ble55ing's blog
blessing the world-
0ctf2019 babyheap--exhaust topchunk
0ctf2019的babyheap–exhaust topchunk
这道题是耗尽topchunk,当top chunk不足以分配需要的size时,会触发malloc_consolidate ,然后加以利用的。
题目描述
存在offbynull漏洞,libc 2.28
题解
exhaust topchunk
首先先耗尽topchunk,申请一个块,将topchunk末位置为0,这样,由于有tcache,0x28,0x38,0x48,0x58先申请完填满tcache。
接下来申请删除就会进fastbin了,注意不要释放最后一块。
malloc_consolidate
功能有二:
检查fastbin并进行初始化;
如果fastbin初始化,则按照一定的顺序合并fastbin中的chunk放入unsorted bin中。
具体如下:
-
判断fastbin是否初始化,如果未初始化,则进行初始化然后退出。
-
按照fastbin由小到大的顺序(0x20 ,0x30 ,0x40这个顺序)合并chunk,每种相同大小的fastbin中chunk的处理顺序是从fastbin->fd开始取,下一个处理的是p->fd,依次类推。
-
首先尝试合并pre_chunk。
-
然后尝试合并next_chunk:如果next_chunk是top_chunk,则直接合并到top_chunk,然后进行第六步;如果next_chunk不是top_chunk,尝试合并。
-
将处理完的chunk插入到unsorted bin头部。
-
获取下一个空闲的fastbin,回到第二步,直到清空所有fastbin中的chunk,然后退出。
如参考资料一中所说。
尝试将topchunk耗尽,看fastbin的合并。
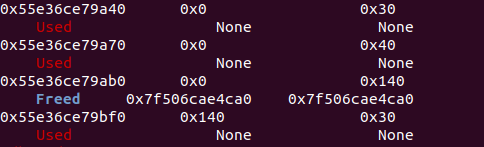
一直申请0x30大小的块直到耗尽,然后将编号1-9的块删除,保留最前和最后两个块,此时topchunk为0x20大小。申请0x40的块,触发合并。
合并、申请完之后,最后一块的prev_size是0x140,然后再利用offbynull将0x140块变为0x100块,然后再在里边申请几个块,把第一个块释放掉,这样在再触发malloc_consolidate时就会将这个块0x140与最后的0x30合并,就构成了overlap。但是这个第一个块是不能在fastbin里的,要在unsortedbin,所以必须先将这个块和之前的一些块合并,触发一次malloc_consolidate再将前面的空间分配出去才行。
由于有个overlap,所以可以通过题目给的View函数泄露libc了。
劫持topchunk
在main_arena+96的地方存着topchunk的位置,通过0x56的堆头地址得到其之前的一个位置(fastbin),然后修改这个topcuhunk的地址,到malloc_hook前面一点的地方,即IO_wide_data_0+301处,找到一个0x7f,将其当做topchunk,然后再申请时切割topchunk就能修改malloc_hook了。当然这题还需要realloc中转一下。
参考资料
-
-
西湖论剑2019的Storm_Note--largebin attack
西湖论剑2019的Storm_Note–largebin attack
当时做完了对largebin有了一个了解,现在又记得不深了,还是补一篇记录出来。
题目分析
题目有一个offbynull,而且给了一个0xABCD0100开始的空间,并且给了一个后门函数,后门函数会比较在0xABCD0100位置的值与输入的值做比较,一样就返回shell,没有show。此题将M_MXFAST设置为0,禁了fastbin。
解题流程
offbynull
首先利用offbynull得到overlap,具体方法为首先构造0x20-0x510-0x20的连续分配,然后在0x510的最后伪造堆头,删除0x510,使用第一个块进行offbynull,然后申请两个块,0x20和0x4e0把0x500的大小分了,把这个0x20和后面的那个0x20删除,就得到了一个0x530的合并大块,其中间是overlap的0x4e0。
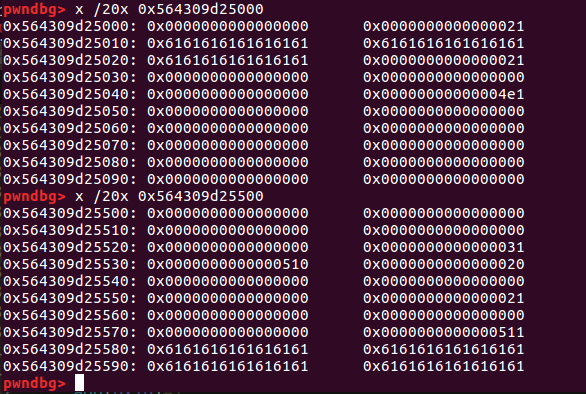
如图为构造的在进行overlap最后堆块合并前的堆空间。
largebin atatck
使用两次overlap,分别从0x530里分出一个0x4f0和0x4e0的块,将申请的0x4e0释放,该块会进入unsorted bin,再释放0x4f0的块,该块也会在unsorted bin,然后申请0x4f0的块,这时会将0x4e0的块放入largebin。

然后通过两个overlap去修改这两个块的指针,使得得到0xABCD0100,然后将其值修改了就ok了。
首先来捋一下接下来申请时的逻辑,目的是将0x56写到0xABCD0100前面一点的地址,然后得到这个块。申请首先找unsorted bin,然后把0x4f0的块放入large bin,然后找它的下一块。在放入largebin的过程中,会将bk的fd和bk_size的fd_size都更新,所以控制0x4e0的bk是fake_chunk+8,bk_size是ake_chunk-0x18-5;0x4f0的bk是fake_chunk。fake_chunk为0xABCD00e0。所以申请0x40时申请到的块如下所示:
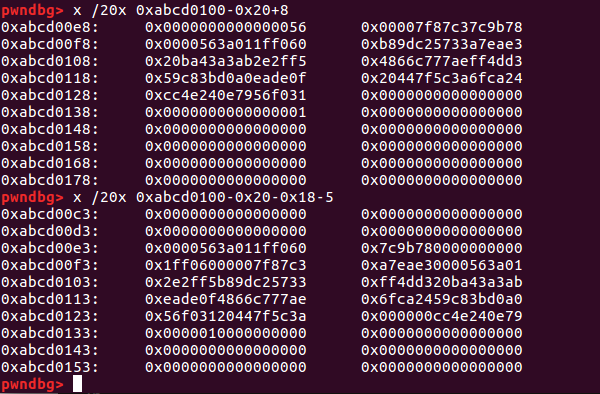
题目文件
由于有一段时间了,就放在这里了https://github.com/ble55ing/ctfpwn/tree/master/pwnable/ctf/x64 Storm_Note
-
cybricsctf Tone
cybricsctf Tone writeup
这个金砖5国ctf真的有意思,有很多新的有趣知识,这道题目是听声音辨别电话号码
zakukozh和battleship就不写wp了,比较常规,前者是文件的逐字节加密,y=ax+b的形式,后者是battleship游戏,电脑会一次打好多炮,可以在save的时候得到对面哪些地方有船的信息,还可以load一次地图。保存的文件一开始有两个字节分别两方的船数,然后后面有一段是每艘船的血量,然后是两个地图,然后最后是两个地图的crc32。根据每次save的结果进行比对就能得到各个位置的作用。
题目的文件可以在这里找到,https://github.com/ble55ing/ctfpwn/tree/master/2019cybricsctf
视频提取音频
现在的播放器很多都提供这种功能,如KMPlayer就是右键->声音->音轨->声音录制,得到MP4,再转成wav格式。
然后拿au打开,看其频谱图,是这样子的:
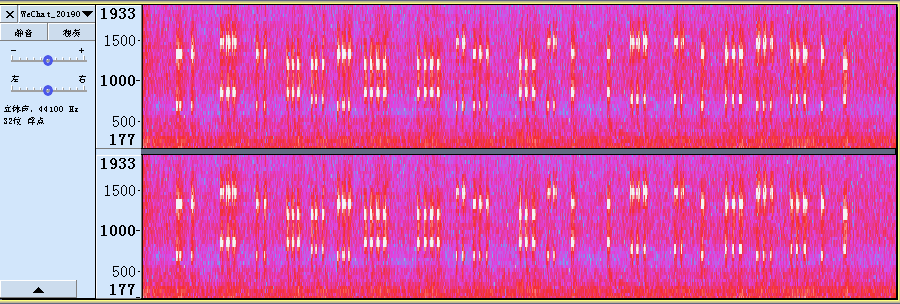
每个音由一个高频一个低频组成,其表如下所示:
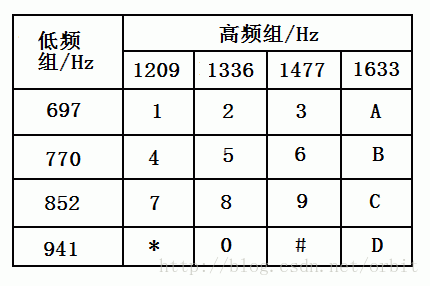
然后照着这个图比对,得到电话号码,222 999 22 777 444 222 7777 7777 33 222 777 33 8 8 666 66 2 555 333 555 2 4。根据9键键盘的输入方式,得到结果cybrics{secrettonalflag}
-
二进制插桩方式探究-x86
二进制程序插桩实践-x86
AFL分析得差不多了,需要来看看LEIF是如何实现的
环境编译
直接make就可以,会报bits/c++config.h: No such file or directory。
使用命令sudo apt-get install gcc-multilib g++-multilib
如果知道使用的是什么版本的gcc的话也可以sudo apt-get install gcc-4.8-multilib g++-4.8-multilib
elf文件格式
使用010edit来分析elf格式,
文件头格式如下:
e_ident Magic,类别,数据,版本,OS/ABI,ABI 16字节 e_type 类型 2字节 e_machine 系统架构 2字节 e_version 版本 4字节 e_entry 入口点地址 4字节 e_phoff 程序头开始 4字节 e_shoff 段头开始 4字节 e_flags 标志 4字节 e_ehsize 文件头的大小 2字节 e_phentsize 程序头大小 2字节 e_phnum 程序头数量 2字节 e_shentsize 段头大小 2字节 e_shnum 节数量 2字节 e_shstrndx 段符串表段索引 2字节程序头格式如下:
p_type; /* Segment type*/ p_offset; /* Segment file offset */ p_vaddr; /* Segment virtual address */ p_paddr; /* Segment physical address */ p_filesz; /* Segment size in file */ p_memsz; /* Segment size in memery */ p_flags; /* Segment flags */ p_align; /* Segment alignment */ 大小均为4字节对于有PIE的32位程序
有PIE了就是程序运行时需要计算偏移了,在插桩的方式上会比较麻烦
文件头的处理
处理文件头。由于需要加一个段,所以将段数+1,(e_shnum),然后程序入口点地址会变化,所以要改e_entry,加0x20,是在程序头中添加的。另外e_shoff也要改,因为前面数据变了,这需要计算。
程序头的处理
LOAD:000000B4 ; PHT Entry 4 LOAD:000000B4 dd 1 ; Type: LOAD LOAD:000000B8 dd 2000h ; File offset LOAD:000000BC dd offset loc_3000 ; Virtual address LOAD:000000C0 dd 3000h ; Physical address LOAD:000000C4 dd 265h ; Size in file image LOAD:000000C8 dd 10268h ; Size in memory image LOAD:000000CC dd 7 ; Flags LOAD:000000D0 dd 1000h ; Alignment
需要添加一个LOAD的程序头,用于存放插桩的代码,所以程序头部分会修改p_filesz和p_memsz,各加0x20。
每个程序头占0x20的空间,表示一个结构,有着地址和大小。
动态符号表的处理
动态符号表也存在因为加了一个程序头而出现偏移的情况,不知道为什么,都是只有_IO_stdin_used需要有地址因此要添加偏移,而别的就不用。
动态符号表之后是字符表,这一部分保持不变。
之后的ELF REL Relocation Table需要添加0x20的偏移。
ELF JMPREL Relocation Table则不用
接下来就是对.text里的代码段进行插桩的实现了。
插桩的实现原理
思想是在jmp类指令之后进行插桩,使用长跳转指令跳到新增加的一个段上去,这样会覆盖5字节的指令,这之后需要恢复这5个字节的内容。
LOAD:00003165 pusha ;两行保存环境 LOAD:00003166 pushf LOAD:00003167 call $+5 ;call下一个地址,就可以获得当前地址了 LOAD:0000316C pop edi ;将call指令的地址存入edi LOAD:0000316D sub edi, 316Ch ;计算程序加载基地址 LOAD:00003173 mov edx, 3245h ;找到插桩点的位置 LOAD:00003178 add edx, edi LOAD:0000317A mov bl, 40h ; '@' ;或的方式进行插桩 LOAD:0000317C mov eax, 321Eh ;存入返回的位置,恢复环境调回去 LOAD:00003181 add eax, edi LOAD:00003183 jmp loc_3000 ;跳入共通的插桩位置 LOAD:00003000 or byte ptr ds:(_GLOBAL_OFFSET_TABLE_ - 1FF0h)[edx], bl LOAD:00003002 jmp eax ;eax, LOAD:0000321E popf ;恢复环境 LOAD:0000321F popa LOAD:00003220 sub esp, 0Ch ;执行被覆盖掉的指令 LOAD:00003223 push 31h ; '1' LOAD:00003225 jmp loc_638 ;返回插桩的位置插桩的思路为:先是保存环境信息,然后找到本桩点对应位置,然后将其置为1,然后恢复运行环境。最后321E的这一段是通用的。
这之后的ELF Initialization Function Table和ELF Dynamic Information的地址也是需要加上0x20的偏移的,即符号表中的部分信息。
再接下来就是插入的信息了,先是代码的部分,
段头的处理
程序的最后面是段头的存储位置,一个段头占用0x28的空间
sh name section名称在字符串Section中的索引 sh_type section种类 sh flags flags sh_addr section运行时虚拟地址 sh offset 名称在文件中的偏移 sh size 大小 sh_link 链接别的section sh_info 额外section信息 sh_addralign section 文件对齐 sh_entsize Entry size if section holds table 每个都是4字节其中,有几种特殊的section段,如下所示
SHN_ABS 0xfff1 该符号包含了一个绝对值,比如表示文件名的符号 SHN_COMMON 0xfff2 表示该符号是一个"COMMON块"的符号,一般来说,未初始化的全局符号定义就是这种类型的。 SHN_UNDEF 0 该符号在本目标文件中被引用到,但是定义在其他目标文件中其他section中都包含其字符串的开始地址。
这部分在插桩中的影响不大,只需要把有地址的其地址加上0x20的偏移即可
遇到的问题
如果程序代码中有
0x56555610 <main+35>: push 0x565556e0这样的情况产生,该指令的汇编码为68 E0 06 00 00那么由于产生了偏移,会导致push的值不正确,而这个值很可能就是函数执行的参数。如这个例子,原先的0x6e0是数据的%d,而之后变成了__libc_csu_fini,导致scanf函数调用失败,就无法正常完成流程了。
.text:000006E0 public __libc_csu_fini ... .rodata:00000700 db 25h ; % .rodata:00000701 db 64h ; d而对于没有pie的程序, 这一部分的参数传递是如下的方式进行的,因而没有产生问题
0x8048505 <main+47>: lea eax,[ebx-0x1a00]对于没有pie的32位程序
编译命令gcc -o easynopie -no-pie -m32 easy.c
首先先处理.text段,使用capstone来得到指令的大小和地址,以及其指令的反汇编内容
//printf("%d %d %d %d\n",offset,all_insn_[offset].id,all_insn_[offset].size,all_insn_[offset].address); //printf("%s %s\n",all_insn_[offset].mnemonic,all_insn_[offset].op_str);处理文件头。由于需要加一个段,所以将段数+1,(e_shnum),然后程序入口点地址会变化,所以要改e_entry,加0x20,是在程序头中添加的。另外e_shoff也要改,需要计算。
在各种数据的计算和处理上也会产生区别,在没有pie的程序的程序上,采用将地址直接从0x8048000提到0x8047000的方式,添加一个页来进行数据的布置,这样能够较好的标出程序原有数据之间的关系而不会出现较多的错误。这样的话相比于有PIE情况的0x20的偏移,没有pie的情况偏移就是0x1000,该方法的实现方案是将第一个Loadable Segment的地址减少0x1000。
然后最后写入文件的时候就是写入文件头,写入程序头,写入插桩后的代码,写入插桩后的新段的代码,写入新的Segment。总的来讲这种方式会相比于有PIE的情况少些错误。
对于有pie的arm程序
前文x86版本的插桩实践
这里来进行一下arm架构程序的插桩实践。
由于arm架构是定长的指令集,所以插桩更易于实现而且效果更好
没有找到arm下不启用pie的方法。。
插桩思路由于arm架构不存在会覆盖其他指令的问题,因而比较简单。主要就是需要解决指令中pc位置的偏移问题。插入的流程还是一样的,找到位置,修改为跳转代码,修改插桩标志、恢复环境、执行原指令,跳转回去。
参考资料
https://blog.csdn.net/king_cpp_py/article/details/80334086
https://blog.csdn.net/weixin_41418994/article/details/83027643
-
arm架构初探
arm架构初探
一直没有涉足过arm呢,走一波
精简指令集
ARM架构是一个32位精简指令集(RISC)处理器架构 ,广泛地使用在许多嵌入式系统设计。具有节能的特点,ARM处理器非常适用于移动通讯领域。相比于x86,ARM往往没有较好的CPU,所以性能相较没有优势;而其流水线指令集的效率会较为优秀,在一些任务相对固定的应用场合其优势就能发挥得淋漓尽致。
寄存器
r0-r3又称为临时工作寄存器,表示可以用来传递参数和返回值,但是不够的话就会用到栈来传递;也称为 a1-a4;callee不需要保存。
r4-r9寄存器可以在函数内部表示局部变量,但如果用到变量的地址,也会类似x86在栈中分配一块;也称为 v1-v6;
r10:sl是栈限制寄存器,当sp递减时不能低于它的值;
r11:fp是栈帧寄存器,和x86的ebp作用类似,用来访问局部变量和参数,而且还保存之前sp的值;
r12:ip,当进入函数时mov ip, sp
r13是sp寄存器;
r14是 lr 返回地址寄存器;
r15是pc (类似EIP) 寄存器。
参数传递
一般采用B系列指令执行函数的跳转执行,其中BL指令将返回地址存储于LR寄存器,BLX指令除了地址存储于LR寄存器,还对要执行的指令进行判断(ARM or Thumb)。
在参数传递时,将所有参数看作是存放在连续的内存单元中的字数据。然后,依次将各字数据传送到寄存器R0~R3中,如果参数多于4个,则通过栈进行存储,入栈的顺序与参数顺序相反,即最后一个字数据先入栈。
局部变量可以存储在寄存器中,也可以有栈来分配。
函数执行完后,若结果32位的整数时,可以通过寄存器返回(一般使用R0)。 64位整数时,可以通过寄存器R0和R1返回,依次类推(不含浮点运算结果)。最后将之前保存的函数地址赋予到PC(可以是LR,也可以是其他寄存器)。
系统调用
在ARM架构上,所有的系统调用都是通过SWI软中断来实现的,指令如下: SWI{cond} immed_24,具体的调用号存放在寄存器R7中,调用函数的参数和之前提到的传参方式相同。例如:
exit(0) MOV R0,#0 MOV R7,#7 SWI #0参考文章
-
arm汇编程序编码格式
arm汇编程序编码格式
常用arm汇编指令
跳转
B指令
MOV PC,xxx,可以在任意4G的空间内做跳转
B 指令,类似于C 语言的jmp,直接向程序计数器PC写入下一跳的地址。
BL指令,类似于C语言的call,将当前位置保存在R14,即LR寄存器,然后在跳转代码结束后通过
MOV PC ,LR跳转回来。B语句是只能在32M的空间跳转,因为其使用的是偏移量,这是一个有符号的26bit数值。
指令编码
.png)
跳转指令的编码格式为,前4个字节是指令的条件码,B指令是1110,即E。之后是3位固定的101,再然后是L标志位,决定是否要保留PC值到LR寄存器。(B和BL 的区别,B是0)。后面的24位是地址偏移,使用有符号的补码表示,然后乘以4(因为每条指令固定4字节)
偏移的计算为:对于目标地址B和当前地址A,[B-(A+8)]/4。如0x8454地址的B loc_8460指令则是0xEA000001
数据处理
MOV指令
将数据从寄存器或者立即数传给目标寄存器
MOV 指令,MOV R0,R1;将R1的值传给R0:0xE1A00001
MOV R0,#1;将立即数1传给R0:0xE3A00001
MVN指令,MVN R0,R1;将R1的值取反传给R0
指令编码
.png)
数据处理指令的编码格式为,前4个字节是指令的条件码,MOV为1110,即E。之后是2位固定的00,再然后是I标志位,区别opcode2是立即数还是寄存器(立即数的话I=1)。后面是4位的opcode1,然后是S标志位,区别该操作是否影响cpsr(S=0不影响)。再后面4位是Rn,第一个操作数的寄存器编码;再后面4位是Rd,目标寄存器编码。后面11位是opcode2,有三种方式:立即数方式,寄存器方式,寄存器移位方式。每种方式下的编码格式不一样 。
立即数方式
前4位是rotate循环右移位,后8位为immed8数值位。
立即数 = immed8在32位上循环右移rotate*2位。只有符合这种构造的才能表示,但是若当把一个数按位取反后,则得到一个合法的立即数时,这个数为有效数。此时将mov指令换成mvn指令执行
寄存器方式
前8位全为0,后4位为寄存器编码
寄存器移位方式
前5位为shift_imm,移动位数大小;后两位为shift,移位方式;然后是1位标志,区分后面Rm使用的是寄存器还是立即数;Rm。
支持5种移位方式,移位次数可由立即数或寄存器给出。
-
LSL:逻辑左移,低位补0
-
LSR:逻辑右移,高位补0
-
ASR:算术右移,高位补符号位
-
ROR:循环右移,移出的低位补入高位
-
RRX:带扩展的循环右移,带C位
如果指令带有S后缀,即S标志位为1,RRX后S标志为移位操作移出的最后一位。
Load/Store指令
LDR指令等,类似于lea指令,将某寄存器中值的某一偏移的位置
.png)
前4位为指令条件码,接下来两位用来区别是批量Load/Store还是非批量的。当为10时,为批量的。为00时,非批量的。然后是6位I、P、U、B、W、L,其他同上。
-
I: 用于区别operand2是立即数(I=1)还是寄存器(I=0)
-
P: 这个位基本在非批量中一直为1.具体内容不清楚
-
U: U=1时,要访问的地址为基址寄存器加上偏移量Address。U=0时, 要访问的地址为基址寄存器减去偏移量Address.
-
B: 当B=1时,指令访问的是无符号的字节数据;当B=0时,指令访问的是字数据
-
W: 当W=1时,将更新基址寄存器的内容(针对事先更新方式)
-
L: 当L=1时,指令执行Load操作。当L=0时,指令执行Store操作
.png)
前索引和后索引
LDR RO,[R1 ,#4] ;[R1+4]->RO
LDR R0,[R1 ,#4]! ;[R1+4]->R0,R1+4->R1
LDR RO,[R1],#4 ;[R1]->RO,R1+4->R1
依然需要+8,如第一条指令就是将R1寄存器中的数+4+8后,取该地址的数值放入R0,如
0x8188 <_start+24> ldr r0, [pc, #0x10]
这条指令,就是取0x8188(PC为当前指令)+0x10+8=0x81a0地址的数据。
注
对于CPSR标志位为:满足cond要求时指令执行,不满足不执行
对于条件码,属于满足条件执行的指令。
.png)
.png)
参考资料
https://blog.csdn.net/gameit/article/details/17464079
-