Welcome to ble55ing's blog
blessing the world-
arm虚拟机环境搭建
arm虚拟机环境搭建
arm的虚拟机运行环境搭建,分文Qemu和arm-linux-gcc两部分。
Qemu+arm
需要大概三样东西,qemu,linux内核,以及busybox的文件系统。
环境安装
sudo apt-get install gcc-arm-linux-gnueabi #交叉编译工具链 sudo apt-get install zlib1g-dev sudo apt-get install libglib2.0-0 sudo apt-get install flex bison sudo apt-get install libpixman-1-dev sudo apt-get install libglib2.0-dev #这五个是Qemu要用到的准备一个文件夹单独用来装环境吧
qemu
先下载Qemu的安装包,
wget https://download.qemu.org/qemu-4.0.0.tar.xz然后对qemu做配置,用以支持模拟arm架构下的所有单板:
./configure –target-list=arm-softmmu –audio-drv-list=
然后编译、安装
make
make install
编译内核
编译内核得到镜像文件zImage
生成面向vexpress的默认config
make CROSS_COMPILE=arm-linux-gnueabi- ARCH=arm vexpress_defconfig
然后编译:
make CROSS_COMPILE=arm-linux-gnueabi- ARCH=arm
然后就可以先试试qemu加载内核,如果能成功显示出来内核的启动信息就是到这里成功了。
qemu-system-arm -M vexpress-a9 -m 512M -kernel linux/arch/arm/boot/zImage -dtb linux/arch/arm/boot/dts/vexpress-v2p-ca9.dtb -nographic -append "console=ttyAMA0"busybox配置文件系统
下载文件
wget http://www.busybox.net/downloads/busybox-1.31.0.tar.bz2然后设置默认配置,编译安装
make defconfig
make CROSS_COMPILE=arm-linux-gnueabi-
make install CROSS_COMPILE=arm-linux-gnueabi-
期间可能会出现scripts/Makefile.build:197: recipe for target ‘loginutils/passwd.o’ failed 这样的错误,这时可以在BusyBox源码的include目录下/libbb.h 文件添加一行引用 #include <sys/resource.h> ,得以解决。
之后全部按照参考资料1中写的,
mkdir -p rootfs/{dev,etc/init.d,lib} sudo cp busybox-1.20.2/_install/* -r rootfs/ sudo cp -P /usr/arm-linux-gnueabi/lib/* rootfs/lib/ sudo mknod rootfs/dev/tty1 c 4 1 sudo mknod rootfs/dev/tty2 c 4 2 sudo mknod rootfs/dev/tty3 c 4 3 sudo mknod rootfs/dev/tty4 c 4 4 dd if=/dev/zero of=a9rootfs.ext3 bs=1M count=32 mkfs.ext3 a9rootfs.ext3 sudo mkdir tmpfs sudo mount -t ext3 a9rootfs.ext3 tmpfs/ -o loop sudo cp -r rootfs/* tmpfs/ sudo umount tmpfs加载文件系统的qemu模拟
之后就可以整合到一起运行了
qemu-system-arm -M vexpress-a9 -m 512M -kernel linux/arch/arm/boot/zImage -dtb linux/arch/arm/boot/dts/vexpress-v2p-ca9.dtb -nographic -append "root=/dev/mmcblk0 console=ttyAMA0" -sd a9rootfs.ext3arm-linux-gcc
arm-linux-gcc
最后发现居然有这种方法,感觉Qemu白调了。 在这个网站上下arm-linux-gcc-4.4.3-20100728.tar.gz
http://arm9.net/download.asp然后tar -xvf 解压
文件在opt/FriendlyARM 里。
按照参考资料2中写的,
sudo mkdir /usr/local/arm sudo cp -r opt/FriendlyARM/toolschain/4.4.3 /usr/local/arm sudo gedit /etc/bash.bashrc添加一行export PATH=$PATH:/path/opt/FriendlyARM/toolschain/4.4.3/bin
然后到这里我的全局变量没有添加上,因而又添加了一波变量:
sudo gedit /etc/profile sudo gedit ~/.bashrc在这两个里添加了环境变量。
然后使用arm-linux-gcc -o hello hello.c 编译,发现少库
error while loading shared libraries: libstdc++.so.6: cannot open shared object file: No such file or direcory。
因此安装库:
sudo apt-get install libstdc++6 sudo apt-get install lib32stdc++6然后就ok了
使用echo $PATH看看是不是有了
安装qemu-arm
sudo apt install qemu-user
然后会报错没有库:/lib/ld-linux.so.3: No such file or directory
然后查了资料,可以这么运行:qemu-arm -L /usr/arm-linux-gnueabi -cpu cortex-a15 hello
或者将程序编译成静态的:arm-linux-gnueabi-gcc -o simple -c simple -static
安装了qemu-arm就可以直接使用命令qemu-arm hello运行arm的程序了
使用arm-linux-gdb调试arm程序
按照参考文献的3中说的
./configure --target=arm-linux --prefix=/usr/local/arm-gdb -v make make install sudo gedit /etc/profile export PATH=$PATH:/usr/local/arm-gdb/bin试验了8.1 ,7.4两个版本,最终还是最新版的8.3安装成功了
然后如何使用:
开一个terminal,qemu-arm -L /usr/arm-linux-gnueabi -cpu cortex-a15 -g 1234 easy
再开另一个terminal,arm-linux-gdb ./easy,然后输入target remote localhost:1234。
就可以愉快的调试啦
参考文章
https://blog.csdn.net/linyt/article/details/42504975?utm_source=blogxgwz8
http://blog.sina.com.cn/s/blog_13279ca6d0102xb0f.html https://blog.csdn.net/kangear/article/details/8635029
-
根据cfg分析afl的路径信息(2)
根据cfg分析afl的路径信息(2)
使用angr构建二进制程序的cfg图的第二部分
前文链接https://ble55ing.github.io/2019/06/20/afl-cfgpath/
上回书讲到,跑了好久没有结果,这回分析了一下原因,是原程序C语言写的,有很多自妇产逐字节比较的内容,在进行编译时,就变成了很多很多的if,导致程序的cfg图非常庞大。因而去优化了一下程序,使用C++来编写,这样就可以通过调用库函数来实现功能,大大的简化了程序流程,就能够愉快的跑起来啦
本文介绍在跑起来之后还遇到的其他问题
CFG图的简化
angr生成的CFG图会在每个函数的调用时生成两条路径,一条是调用了函数的一条是没调用的。这显然是不合适的,由于函数本身其时不可能不进行该函数的调用,所以要将跳过该函数的路径除去。
CFG图的情况
如果是完整的cfg图(full)的话就是这样的操作了,但这里的不计算库函数的,所以需要区分库函数和程序声明的函数。具体的区分方法为,库函数会在cfg图的dot文件中表示为其plt表的地址,然后有唯一一条路径指向0x1000xxx的地址的一个基本块(也不是全部,比如这次fgetc和fopen,没有这个0x1000xxx的地址),在这个基本块里才有函数名称;而对于程序声明的函数在其函数体的第一个基本块就会有该函数的名称。
296 [fontname=monospace, fontsize=8.0, height=0.65278, label=<{ <TABLE BORDER="0" CELLPADDING="1" ALIGN="LEFT"><TR><TD >0x4008e0</TD><TD >(0x4008e0)</TD><TD></TD><TD></TD></TR></TABLE>|<TABLE BORDER="0" CELLPADDING="1" ALIGN="LEFT"><TR><TD ALIGN="LEFT">0x004008e0: </TD><TD ALIGN="LEFT">jmp</TD><TD ALIGN="LEFT">qword ptr [rip + 0x202762]</TD><TD></TD></TR></TABLE> }>, pos="10186,1.573e+05", shape=Mrecord, width=3.4861]; 296 -> 305 [color=blue, fontname=monospace, fontsize=8.0, pos="e,10186,1.5722e+05 10186,1.5727e+05 10186,1.5726e+05 10186,1.5724e+05 10186,1.5723e+05"]; 305 [fillcolor="#dddddd", fontname=monospace, fontsize=8.0, height=0.51389, label=<{ <TABLE BORDER="0" CELLPADDING="1" ALIGN="LEFT"><TR><TD >0x1000030</TD><TD >(0x1000030)</TD><TD ><B>__stack_chk_fail</B></TD><TD >SIMP</TD></TR></TABLE> }>, pos="10186,1.572e+05", shape=Mrecord, style=filled, width=3.4306]; 305 -> 305 [color=orange, fontname=monospace, fontsize=8.0, pos="e,10309,1.5719e+05 10309,1.5722e+05 10320,1.5721e+05 10327,1.5721e+05 10327,1.572e+05 10327,1.572e+05 10324,1.5719e+05 10319,1.5719e+\ 05"];如
__stack_chk_fail函数,其调用是对296块的调用,然后296中并没有表示其函数名,事实上这个是__stack_chk_fail函数的plt表位置,而又唯一出路径296->305,305中保有其函数名。这个305-> 305的自调用是很特殊的,其实目前只发现
__stack_chk_fail和exit这种不正常退出的函数会有。0 [fontname=monospace, fontsize=8.0, height=1.5556, label=<{ <TABLE BORDER="0" CELLPADDING="1" ALIGN="LEFT"><TR><TD >0x4009d0</TD><TD >(0x4009d0)</TD><TD ><B>main</B></TD><TD></TD></TR></TABLE>|<TABLE BORDER="0" CELLPADDING="1" ALIGN="LEFT"><TR><TD ALIGN="LEFT">0x004009d0: </TD><TD ALIGN="LEFT">lea</TD><TD ALIGN="LEFT">rsp, qword ptr [rsp - 0x98]</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x004009d8: </TD><TD ALIGN="LEFT">mov</TD><TD ALIGN="LEFT">qword ptr [rsp], rdx</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x004009dc: </TD><TD ALIGN="LEFT">mov</TD><TD ALIGN="LEFT">qword ptr [rsp + 8], rcx</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x004009e1: </TD><TD ALIGN="LEFT">mov</TD><TD ALIGN="LEFT">qword ptr [rsp + 0x10], rax</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x004009e6: </TD><TD ALIGN="LEFT">mov</TD><TD ALIGN="LEFT">rcx, 0xbb94</TD><TD></TD></TR><TR><TD ALIGN="LEFT">0x004009ed: </TD><TD ALIGN="LEFT">call</TD><TD ALIGN="LEFT">0x4020e0</TD><TD></TD></TR></TABLE> }>, pos="9883.5,1.8988e+05", shape=Mrecord, width=3.6389];而程序声明的函数则不会出现这种情况,因为不是通过plt表做的调用。如上是main函数的表示,这是一个main函数开始的第一个基本块。
预处理
鉴于上述问题,需要对CFG图进行预处理,实际上这个预处理的功能很大程度上提升了效率。。
预处理的内容为:
1将所有调用库函数的路径消去;
2将所有调用
afl_maybe_log、__afl_maybe_log0等函数的路径消去 3将所有调用程序声明函数而没进入的路径消去
消去上述三种路径后,分析块多了。。
内部处理
关于循环
循环会导致在进行总的路径提取时陷入循环,所以需要进行处理
处理的方式分为while型和do-while型,即有第一个基本块判断是否达到条件跳出循环的也有最后一块判断的。前者的特征是2进2出,后者是1进2出,都是会构成环路的情况。目前暂定的处理方式为:将循环分为走0遍和走1遍的情况进行路径的处理,再走第二遍的时候就跳出循环。前者由于在第二次到达时就已经走过一遍循环体了,直接返回就行了;而后者触发第二次到达的是循环中的第一个基本块,所以要找到这个基本块的前一跳的基本块然后跳出去。
上述的这种方式感觉效果不佳,。。而且其实while型和do-while型区别不大。所以决定采用在第三次到达某一位置时,查看这次到达是否在之前存在过的形式来判断。如果这种形式之前存在了,则舍弃这次跳转。
关于自循环
在CFG图中发现了一些自循环的基本块,如repe cmpsb这样的指令,由于出度有两个,直接忽略掉去自循环的调用关系就好了。
-
starctf2018 babystack
starctf2018 babystack writeup
这是一道有趣的题目。一直以来,绕过stack canary是通过逐位爆破的方式进行的,总是想着,是否有一种方法,能够更改stack canary中的值,这样就能够直接绕过stack check了。
这就是这样的一道题目。
题目描述
题目本身关了ASLR,并会创建一个线程,线程中会读一个长度然后写入栈中。
很明显会有一个栈溢出。
题目调试
使用gdb加载程序,然后b在线程调用的读入数据的函数内部。单步程序,输入过长的数据,查看堆__stack_chk_fail的调用,

可以看到这里是存储在fs:[0x28]中。gdb中可以通过info all-registers来查看所有寄存器中的值,但是并没有这个。。这个fs寄存器是由glibc定义的,存放Thread Local Storage (TLS)信息的,该结构体如下所示:
typedef struct { void *tcb; /* Pointer to the TCB. Not necessarily the thread descriptor used by libpthread. */ dtv_t *dtv; void *self; /* Pointer to the thread descriptor. */ int multiple_threads; int gscope_flag; uintptr_t sysinfo; uintptr_t stack_guard; /* canary,0x28偏移 */ uintptr_t pointer_guard; …… } tcbhead_t;这个stack_guard 是在
__libc_start_main中进行设置和赋值的,首先以_dl_random这个全局变量为入参(有没有可能得到这个值然后能够绕过canary),生成canary,然后通过THREAD_SET_STACK_GUARD宏将canary赋值给tls的stack_guard变量。题目解法
在使用pthread时,这个TLS会被定位到与线程的栈空间相接近的位置,所以如果输入的数据过长的话也可以把这里覆盖掉,就可以改掉stack_guard的值了。
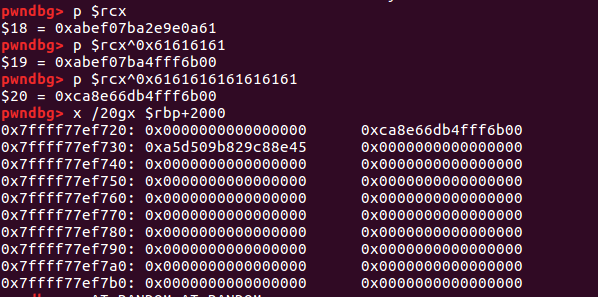
rcx中是xor之后的值,再异或回去就是了,可以看到原先的stack_guard是在$rbp+2008的位置。
扩展研究
stack canery的生成流程,即如何将stack canary的值生成并放入fs:[0x28]的
这一部分是在security_init 函数里,该函数开始的地方位于<dl_main+6725> 。

这个值的生成是从
_dl_random这个随机数生成的,它由_dl_sysdep_start函数从内核获取的。_dl_setup_stack_chk_guard函数使用这个随机数生成canary值,THREAD_SET_STACK_GUARD宏将canary设置到%fs:0x28位置。198 /* Set up the stack checker's canary. */ 199 uintptr_t stack_chk_guard = _dl_setup_stack_chk_guard (_dl_random); 200 # ifdef THREAD_SET_STACK_GUARD 201 THREAD_SET_STACK_GUARD (stack_chk_guard); 202 # else 203 __stack_chk_guard = stack_chk_guard; 204 # endif总的来说,kernel初始化了跟TLS相关的寄存器gs, 并 且提供了canary这个随机值, glibc写入%gs:0x14这个保存随机值的位置并且提供变量定义和 打印函数定义, 最上面是gcc插入对canary的值的引用和出错函数到用户代码里.
参考文章
-
根据cfg分析afl的路径信息
根据cfg分析afl的路径信息
前文使用angr获取了二进制程序的cfg图,接下来要依据控制流图,提取出afl的路径信息。
前文链接:https://ble55ing.github.io/2019/06/18/angr-cfg/
先提取普通的cfg图
首先还是要使用angr进行分析,得到描述cfg的dot文件
然后要对dot文件进行处理,提取有用的部分。有用的部分分为三种:当前处理基本块的id,基本块间的上下文关系和基本块中的汇编指令。前两项是要记录的,后面的汇编指令要处理。
处理的部分首先是获得各个函数的地址和名称,以及main函数的id。(这个后面感觉好像没什么用)
然后获取哪些基本块中被afl插入了以及其随机数。并将所有是afl添加进来的块的id记录下来,以便在后面将afl中的互相调用删去(不对这里好像有问题)仔细分析了一下angr生成的cfg描述,精简的解决方式为以
__afl_maybe_log为目标的分支直接删去,因为angr是为每个调用函数都生成一个分支的,我们不用去考虑调用__afl_maybe_log之后在其函数内部的逻辑,而且最终这个分支还是会回去的。所以没问题。然后就是顺着每一条路径,找到其中被afl插入的位置,按照AFL的分支计算逻辑来计算一下分支的情况。改天再验证一下出来的结果是否正确。
额复杂程序分析时内存不够你敢信。。OSError: [Errno 12] Cannot allocate memory
额然后虚拟机就启动不起来了
[/dev/sda1: clean, */* files, */* block,Ctrl Alt +F2进命令行看看。df -h。竟然空间全占满了。删一个文件然后sudo rm -rf ~/.local/shared/Trash/*。reboot重启,等以会儿。。好了。但这样下去就没法运行了。。只好新建一个虚拟机,待续
后文链接
有后续了
-
使用angr构建二进制程序的cfg
使用angr构建二进制程序的cfg
使用angr构建二进制程序的cfg图。
主要目标是分析afl是如何进行基本块的划分的,然后发现angr的静态分析流程图会更细一些,IDA适中,AFL更粗一些。
对所有基本快来说,入度可以很多,但出度最多为2。
对于较大的程序,angr的Accuracy的full生成方案需要相当的内存。
生成可视化的CFG图
使用CFGFast
CFGFast是一种静态缝隙生成控制流图的方案,会比较的Fast。
def cfgfastpng(filename) proj = angr.Project(filename,load_options={"auto_load_libs":False}) print("----------static-----------") cfg = proj.analyses.CFGFast() plot_cfg(cfg, filename, asminst=True, remove_imports=True, remove_path_terminator=True)# 该函数默认产出格式为pngCFGFast生成的cfg图中,在每一处库函数的调用的时候都会产生一个新的块,感觉在后续处理的时候,需要去掉。
使用CFGAccurate
CFGAccurate和CFGFast也是一样的细度,这就是angr的模块分类方式吧,但CFGAccurate出来的流程图要大好多,原因是其很多重复的块,因为CFGAccurate中保存了块之间的上下文调用关系,用于上下文切片会产生号的效果吧,且CFGAccurate没有添加__libc_csu_init这样的地址。
fast和acc的区别在于, 对于fast,如果两个不同的地方都调用了printf,那么在fast中,就会产生两个由printf出去的路径,结果就是本来两个互相之间不能达的地方就变得能够到达了。
直接给出官方的实例的修改版,我使用的angr版本里建议使用main_object替换main_bin,并使用relative_addr, linked_addr, or rebased_addr替换了之前的addr
#! /usr/bin/env python import angr from angrutils import plot_cfg def analyze(b, addr, name=None): start_state = b.factory.blank_state(addr=addr) start_state.stack_push(0x0) cfg = b.analyses.CFGAccurate(fail_fast=True, starts=[addr], initial_state=start_state, context_sensitivity_level=2, keep_state=True, call_depth=100, normalize=True) for addr,func in proj.kb.functions.iteritems(): if func.name in ['main','verify']: plot_cfg(cfg, "%s_%s_cfg" % (name, func.name), asminst=True, vexinst=False, func_addr={addr:True}, debug_info=False, remove_imports=True, remove_path_terminator=True) plot_cfg(cfg, "%s_cfg" % (name), asminst=True, vexinst=False, debug_info=False, remove_imports=True, remove_path_terminator=True) plot_cfg(cfg, "%s_cfg_full" % (name), asminst=True, vexinst=True, debug_info=True, remove_imports=False, remove_path_terminator=False) if __name__ == "__main__": proj = angr.Project("test1", load_options={'auto_load_libs':False}) main = proj.loader.main_object.get_symbol("main") analyze(proj, main.rebased_addr, "test1")该示例显示生成了三种图,一种是只有main函数的图test1_main_cfg.png,一种是全函数调用的图test1_cfg.png,还有一种是test1_cfg_full.png的图,显示更加详细的信息。
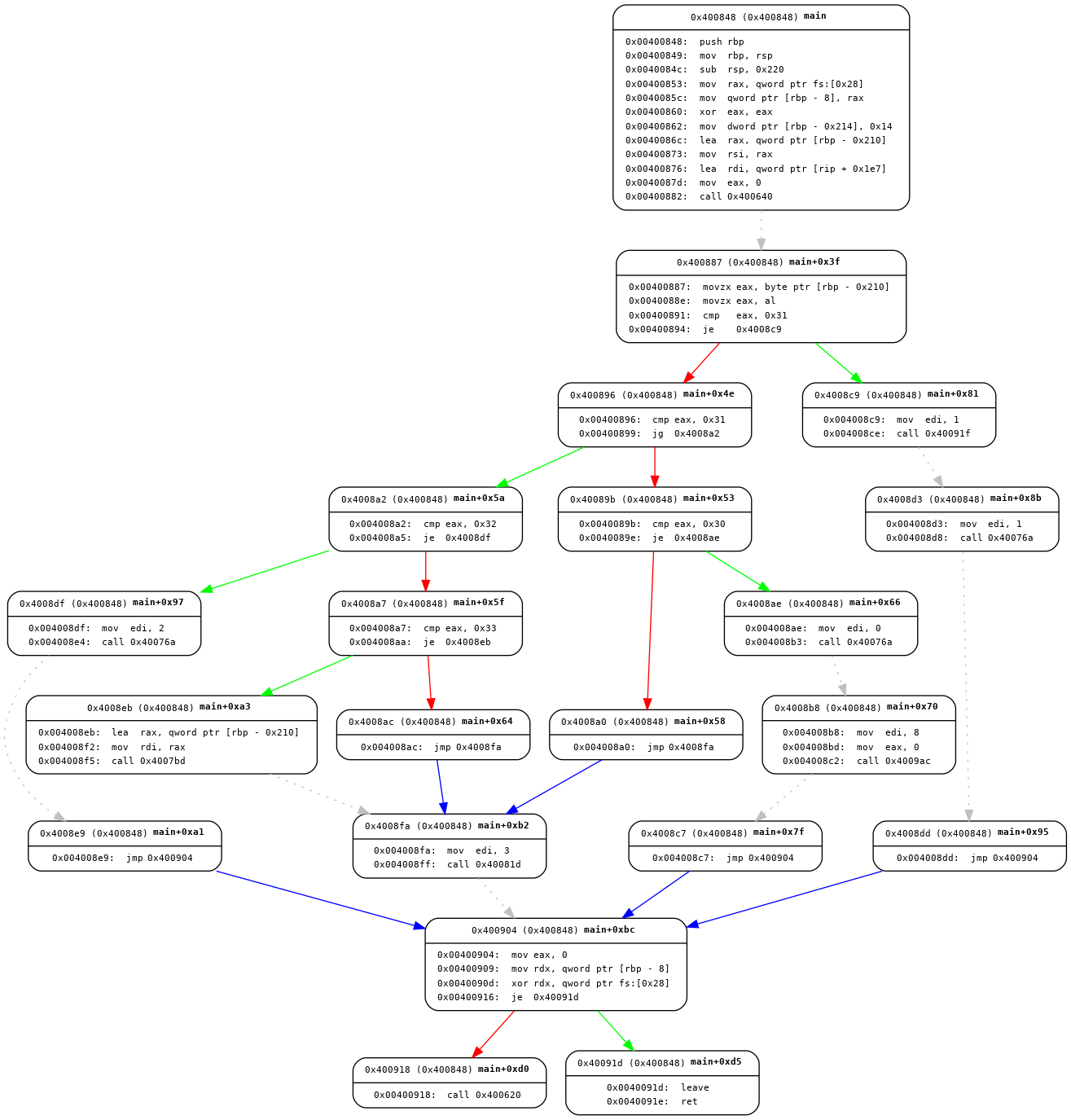
test1_main_cfg.png
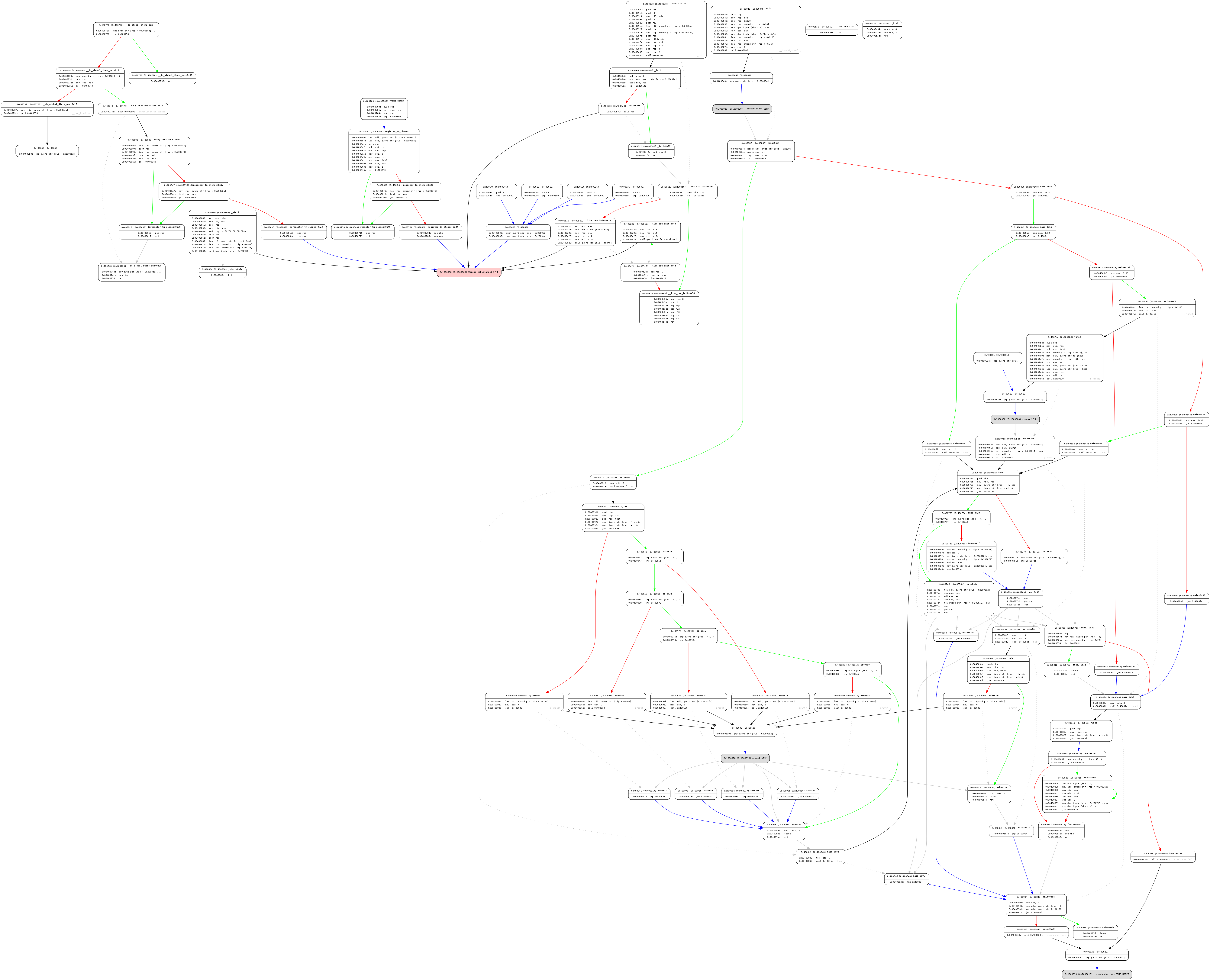
test1_cfg.png
test1_cfg_full.png
可以看到就算是很小的程序,它的cfg图也相当庞大了
生成格式描述的cfg图
angr在这方面封装好了,但从图片中提取信息实在是不容易。。所以找了一下有没有能够获取创建cfg图时用到的dot文件的方法(毕竟安装graphviz和pygraphviz也是废了一番功夫的)。
因此去翻了一下plot_cfg函数的源码
def plot_cfg(cfg, fname, format="png", path=None, asminst=False, vexinst=False, func_addr=None, remove_imports=True, remove_path_terminator=True, debug_info=False): vis = AngrVisFactory().default_cfg_pipeline(cfg.project, asminst=asminst, vexinst=vexinst) if remove_imports: vis.add_transformer(AngrRemoveImports(cfg.project)) if func_addr: vis.add_transformer(AngrFilterNodes(lambda node: node.obj.function_address in func_addr and func_addr[node.obj.function_address])) if debug_info: vis.add_content(AngrCFGDebugInfo()) if path: vis.add_edge_annotator(AngrPathAnnotator(path)) vis.add_node_annotator(AngrPathAnnotator(path)) vis.set_output(DotOutput(fname, format=format)) vis.process(cfg.graph)可以看到其参数里是有format的,把format设置为dot就能得到其描述语言版的cfg图了,有每个块的汇编指令。
angr的cfg图特性分析
angr会在每一个call的时候分出两个分支出来,如下面0x400800是main函数的开始地址,第一个块到0x40081d,然后会分成两个块,
__afl_maybe_log的块和0x400b22的块,最后__afl_maybe_log的块也会回到0x400822所有没问题。.text:0000000000400800 lea rsp, [rsp-98h] .text:0000000000400808 mov qword ptr [rsp+98h+buf+180h], rdx .text:000000000040080C mov qword ptr [rsp+98h+buf+188h], rcx .text:0000000000400811 mov qword ptr [rsp+98h+buf+190h], rax .text:0000000000400816 mov rcx, 140Fh .text:000000000040081D call __afl_maybe_log .text:0000000000400822 mov rax, qword ptr [rsp+98h+buf+190h] .text:0000000000400827 mov rcx, qword ptr [rsp+98h+buf+188h] .text:000000000040082C mov rdx, qword ptr [rsp+98h+buf+180h] .text:0000000000400830 lea rsp, [rsp+98h] .text:0000000000400838 sub rsp, 238h .text:000000000040083F mov edi, offset unk_402454 .text:0000000000400844 mov rax, fs:28h .text:000000000040084D mov [rsp+238h+var_10], rax .text:0000000000400855 xor eax, eax .text:0000000000400857 lea rsi, [rsp+238h+buf] .text:000000000040085C call ___isoc99_scanf .text:0000000000400861 movzx eax, [rsp+238h+buf]
-
AFL的覆盖率分析
AFL的覆盖率分析
AFL是逃不过的,看一看看一看。
找起来才发现,AFL的插入位置感觉并不多
覆盖率
https://github.com/mrash/afl-cov 这是一款显示AFL实时覆盖率信息的工具,显示Lines,Functions和Branches
分支信息
AFL使用二元元组进行分支流程的记录。
AFL对每个插桩处生成一个0到MAP_SIZE之间的随机数,为这一块的位置记录。
AFL会保存期前一个位置的信息__afl_prev_loc ,然后与当前位置异或,为分支的对应信息。
" movl __afl_prev_loc, %edi\n" " xorl %ecx, %edi\n" " shrl $1, %ecx\n" " movl %ecx, __afl_prev_loc\n"上述代码中,ecx为当前位置生成的随机数,AFL会将当前位置右移1位之后再保存在__afl_prev_loc里,官方解释这是用于使A->A这样的跳转不为0,也是为了区分A->B和B->A。
AFL使用hashmap来存储这些随机数,该hashmap保存在共享内存中,且AFL还会在界面中显示出当前hashmap的密度。如果密度过大,那碰撞概率就会很高,解决方案见官方文档。
在每次调用
__afl_maybe_log或者__afl_maybe_log0来进行该处执行信息的记录的时候,都会先mov一个数到rcx,这就是那个随机数。crash去重
在crash去重方面,AFL是采用这样的方法:如果符合下列情况之一,认为其唯一:
- The crash trace includes a tuple not seen in any of the previous crashes
- The crash trace is missing a tuple that was always present in earlier faults.