Welcome to ble55ing's blog
blessing the world-
从零开始aeg
环境配置
各种环境的配置,起源于强网杯的babyaeg,另外可能考虑做一下之后强网杯的AI aeg。
环境一
pypy
pypy是一个高效的python脚本优化器。
sudo apy-get install pypy
然后pypy使用的包和python是独立的,所以需要把python的支持包拷贝一份到pypy,位置是
cp -R /usr/local/lib/python2.7/dist-packages /usr/local/lib/pypy2.7/ cp -R /usr/local/lib/python2.7/site-packages /usr/local/lib/pypy2.7/这样还是不够的,总需要有安装新的第三方库,因而要给pypy安装pip,安装方法为pypy get-pip.py,get-pip.py的地址为**地址,安装完之后pip就只给pypy安装了。有源码的可以通过pypy setup.py install的方式进行,
-
Directed Greybox Fuzzing
Directed Greybox Fuzzing分析
当前进展
定向符号执行(DSE) 效率低,工具Katch(针对补丁的测试工具),引擎BugRedux
定向灰盒模糊器(DGF)的工具AFLGo 好得多
OSS-Fuzz 是一个针对安全关键库和其他开源项目的持续测试平台 。
2017年ACM会议
本文内容
在本文中,我们介绍了定向灰盒模糊控制(DGF) ,它的重点是到达一组给定的目标位置在程序中。 在高层次上,我们将可达性强制转换为最佳化问题,并使用一种特殊的启发式算法来最小化生成的种子到目标的距离。 为了计算种子距离,我们首先计算和测量每个基本块到目标的距离。 虽然种子距离是过程间的,但是我们的新方法只需要对调用图进行一次分析,而对于每个过程内的 CFG 只需要进行一次分析。 在运行时,模糊器聚合每个运行的基本块的距离值来计算种子距离作为它们的平均值。 DGF用来使种子间距最小化的元启发式算法被称为模拟退火算法[19] ,并以功率调度的形式实现。 能量计划控制所有种子的能量[6]。 种子的能量特性决定了种子fuzzing的时间。 与所有灰盒模糊技术一样,通过将分析移动到编译时,我们可以最小化运行时的开销
Dgf 将目标位置的可达性转换为最佳化问题,而现有的定向(白盒)模糊方法将可达性转换为迭代约束补偿问题。
本文的定向灰盒模糊是基于CG和CFG的,使用距离测量和基于退火的功率调度的实现方法,在补丁测试和crash复制领域很有用
本文的主要工作:
- 灰盒模拟和模拟退火的集成
- 一种跨过程的距离的正式测量方法,可以同时考虑多个目标,可以在测量时有效地预先计算,并在运行时得到最佳结果
- 将定向灰盒模糊作为 AFLGo 实施,该功能在 https://github.com/AFLGo/AFLGo 公开提供,
- 将 AFLGo 作为补丁测试工具整合到 OSS-Fuzz 的全自动化工具链中,该工具在 https://github.com/AFLGo/OSS-Fuzz 公开发布
- 大规模评估定向灰盒燃烧作为补丁测试和碰撞复制工具的效率和实用性
实现方案
将函数 n 与目标函数 Tf 之间的函数级目标距离 df (n,Tf)定义为 n 与任意可达目标函数 Tf 之间函数距离的调和平均值
模拟退火(SA) 是一种马尔科夫蒙特卡洛方法(MCMC) ,用于在一个可接受的时间预算内,在一个非常大的,通常是离散的搜索空间内,逼近全局最优解。 的主要特征
先通过将一个函数的所有调用位点与被调用函数的第一个基本块连接起来,构造跨过程控制流图(iCFG)。 这需要几个小时。 一旦有了 iCFG,它将计算每个基本区块在 iCFG 内的目标距离,作为通往任何目标的最短路径的平均长度。这也可能需要几个小时。 Bb-level 目标距离的核心是基于 Djikstra 的最短路径算法,该算法的最坏情况复杂度为 o (v2) ,其中 v 为节点数。
怎么感觉这么熟悉。。
-
面向二进制程序的漏洞挖掘关键技术研究分析
面向二进制程序的漏洞挖掘关键技术研究分析
······王铁磊大佬的论文分析
国内在软件安全漏洞挖掘方向比较活跃的机构包括中国信息安全测评中心、中国人民解放军总参谋部、北京大学、中国科学院软件所、北京邮电大学、解放军信息工程大学、国防科学技术大学、北京理工大学、哈尔滨工业大学、武汉大学等机构和院校。这些单位在漏洞挖掘和管理等方面取得了一定的成绩,但在零日漏洞发现的数量、国际顶级会议论文数、漏洞库的有效利用、漏洞响应管理等方面与美国相比还有较大距离。
论文关注的研究现状
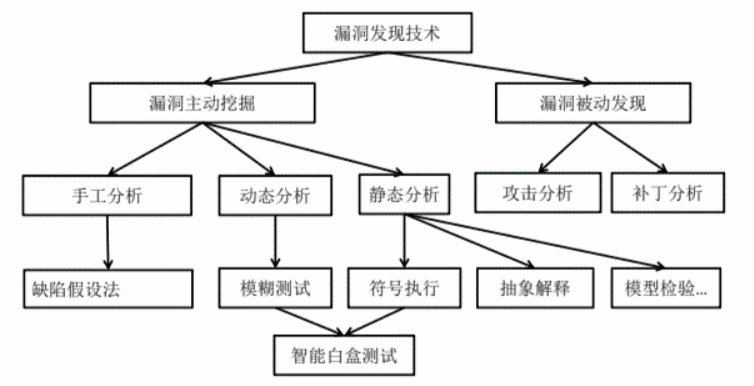
总体图,接下来分类介绍
被动发现
1.蜜罐
一种安全资源,防被扫描、攻击和攻陷。。
捕获攻击,针对漏洞攻击逆向分析。
2.基于补丁的漏洞发现技术
比对二进制文件,定位补丁修复点
主动挖掘技术
1.手工漏洞发现技术
2.静态漏洞发现技术
数据流挖掘技术:解决空指针解引用、内存多次释放的问题。斯坦福大学的MC系统,和其孵化出的代码静态扫描软件Coverity已被应用。同样可用于处理格式化字符串漏洞,但CQual好像有局限性。
自动机可描述漏洞模式,结合软件模型理论遍历代码空间,检测疑似安全漏洞,如UNO,MOPS,SLAM。此处有两图的文字介绍
时序安全漏洞(TemporalVulnerability)是–种典型的可以用自动机刻画的漏洞类型。程序执行过程中很多操作(例如API调用)应该满足严格的时序关系:一旦执行过程中这种时序关系被破坏,就对应一个潜在安全问题。MOPS用下推自动机(Pushdown Automata)PDA表示程序控制流图,用有限状态自动机FSA刻画安全漏洞。下推自动机本质上是一个带有堆栈数据结构的有穷自动机。下推自动机的这种特性很容易用于表示函数间的调用关系。判断程序是否违反安全属性的问题转换为判断两个自动机求交是否为空的问题,MOPS系统能够做到检测结果无漏报(完备性),但是MOPS是数据流不敏感的分析,无法跟踪数据依赖关系,导致MOPS误报率很高。
与MOPS系统类似,SLAM是一种基于谓词抽象技术的软件模型检验器,主要用于检测Windows操作系统驱动程序是否满足用户定义的属性;约束。SLAM的核心技术是谓词抽象,将每个变量都抽象为只有0/1两种取值。这种过近似(Over-Approximations)抽象方法导致SLAM误报较为严重。所以微软将SLAM集成到Windows驱动开发平台中,在驱动开发阶段生成编译警告,辅助开发人员发现安全隐患。
复杂数据约束关系模式:抽象解释理论->符号执行技术(开放性难题)
3.动态漏洞挖掘技术
事件空间遍历:CMC通过枚举不同事件(收到报文、通信超时、内存分配失败)。同样FiSC应对文件系统,从空磁盘开始,每个状态枚举所有可能的操作(文件创建删除、磁盘镜像挂载卸载,及各种格式)
输入空间遍历:处理海量数据(fuzz)
程序执行路径遍历:样本生成。混合符号执行和细粒度污点分析。
本文的主要工作
提出绕过校验和防护机制的方法。
提出了roBDD离线细粒度污点分析技术,降低了细粒度污点分析内存需求
提出了基于细粒度污点分析的导向性样本生成方法。以及基于混合符号执行的智能样本生成方法。
提出了一种整数溢出漏洞模型,并配套设计了二进制程序的脆弱性构件识别方法,结合基于惰性检测的挖掘方法,有效缓解路径爆炸。
roBDD离线细粒度污点分析技术
TaintReplayer,基于二进制植入平台Pin实现
BDD 二元决策树,除终点外出度均为2
详情见roBDD那篇论文的分析
二进制程序的混合符号执行技术
污点分析只记录了传播,没记录关系。如果在某处,某变量被重新赋值为常数,那么应当去掉其关系。
符号执行的问题:
1.符号执行需要符号计算系统的支撑,硬件要求高,没有好办法,制约了其发展
2. 无法处理循环或递归,如果边界条件中有符号变量,很难确定其次数
3.没有源代码难以处理系统API的调用问题
4. 符号在处理矢量数据单元(数组)时面临挑战
Prefix/Prefast已经成为微软内部标准源代码静态检测工具之一。源码->AST->拓扑排序->为每个过程生成相应模型,最后静态模拟执行路径并用约束求解进行检验。这是一种过程间的符号执行,有效检测指针变量使用的相关漏洞。路径结束时检测路径上是否存在资源泄露,合并路径结果,建立摘要,再打开的时候就可以直接应用,加速模拟。
混合符号执行:运行时判断哪些代码需要经过符号执行,这样一来符号执行被充分利用了程序的运行时信息,提高了分析准确性。
代码植入是混合符号执行的重要支撑
有源码符号执行
EXE和DART都是基于源码植入平台CIL实现,KLEE是基于LLVM实现的。
存在过度依赖源码、针对单一语言、运行平台,无法评估第三方模块的问题。
面向二进制程序的符号执行
在线符号执行、离线符号执行
面向底层指令和面向中间代码的符号执行。
在线符号执行基于二进制代码植入技术,这很容易导致破坏原逻辑,尤其是代码混淆过的或者并发、多线程的情况。
离线符号执行指先计算程序执行轨迹,再在轨迹重放时进行符号计算。
中间代码的符号执行:SymReplayer。基于中间语言VEX
校验和感知模糊测试
现有模糊测试中的约束规范生成系统:SPIKE,PEACH,Protos。
校验和检测点特征分析
对于一般的检测形式,H(D)==T(C)
ffdds
-
大量真实程序分析得到,程序需要做big-endian到little-endian的转换。
- 高依赖度。D关于全体,C关于几个字节
- 行为差异性:随机生成的总为False,标准样本总为True
- 无负效应性,C用完之后就没用了
所以具体来说,方式为:找到正常样本中高污点依赖分支,找到畸形样本中高污点依赖分支,定位程序差异点,识别校验和域。类似于Tupni的校验和域识别方法
关于特例:有可能样本是分多个块的,然后每个快单独计算校验和;也有一个检测会需要多个分支点的情况,如MD5在32位体系需要4个int进行检验,
本文的解决办法:TaintScope会特别跟踪被修改的字节,只有一个分支语句即满足高污点依赖,又受修改字节影响时,才记录该分支;使用Bestar来查找复合分支结构,如果其中一个分支点被定义为检查点,则进一步检查该复合分支中的其他谓词。
一般,3-5个正常样本和10几个畸形样本足够定位校验检查点
校验和自动修复技术
校验和感知的模糊测试技术主要由三部分构成。首先,TaintScope在细颗粒度污点分析的基础上,识别程序执行过程中的高污点依赖度分支点,并进一步定位目标程序处理正常样本和急性样本时的路径执行差异点,准确识别校验和检测点;接下来,TaintScope在校验和检测点修改目标程序,禁止目标程序检测输入数据的完整性。TaintScope生成大量畸形数据,对修改后的目标程序进行测试。最后,针对导致修改后程序崩溃的畸形样本,TaintScope在混合符号 执行技术的基础上,增加了对符号地址的推理,实现了校验和自动修复技术,能够修复畸形样本,使之通过原始程序的校验和检查。
测试时尝试只修改校验和域,查看H(D)是不是没有变化,没有变化说明是对的。
总的来说,本文的方法不适用于消息认证码和数字签名,能识别也无法生存正确的,所幸用的不多。
混合符号执行能够对执行轨迹进行深度的安全分析,因为到达malloc的样本也不一定能够触发整数溢出漏洞。混合符号执行就能够带符号值计算其是否可能触发了,但混合符号执行的效能还是不太有效。
由于混合符号执行技术在整数溢出漏洞上表现出了较好的效果,因而接下来文章重点介绍了这方面的内容。
对于二进制程序的整数溢出中遇到的困难:
-
二进制程序难以准确确定变量类型,unsigned还是signed之类的
-
二进制程序中程序调用不明确,caLL rax这种静态分析很困难
-
二进制程序无害的整数溢出非常普遍。由于整数溢出本身不构成对程序的破坏,程序员甚至编译器会故意利用整数溢出溢出。例如,GCC编译器在O2优化选项下,会把源代码if(x >= -2 && x<=0x7ffffffd)编译生成:
mov eax, x; // eax=x add eax, 2; // eax = eax+2 js target这段二进制代码中,将源程序中两个谓词判断简化为-一个谓词判断,虽然极大的x会使add指令会发生溢出,GCC正是利用了溢出的性质,简化了谓词判断。检测过程中,不能将这种对程序不造成破坏的良性溢出识别为整数溢出漏洞。
基于细粒度污点分析的导向性样本生成
如BMP,像素的改变并不会触发异常,头控制信息才会影响分配。
导向性就在于此,变异这些敏感的位置。在保留原始样本的正常结构时,将关键数据片段修改为异常的值。
总结
本文以面向二进制程序漏洞挖掘为总体目标,针对静态分析高误报率、静态符号执行面临的执行空间爆炸和校验和机制导致模糊测试失效等问题,重点研究了细颗粒度污点跟踪、混合符号执行、校验和感知模糊测试、反馈式畸形样本生成、整数溢出漏洞建模与检测等关键技术,对上述问题提出了解决方法。
- 提出了一种校验和感知的模糊测试技术。该技术综合运用了混合符号执行与细颗粒度动态污点跟踪,自动定位程序中校验和检测点、修复畸形样本的校验和域,成功绕过程序中的校验和检查机制。
- 提出了两种反馈式畸形样本生成技术:基于细颗粒度污点分析的导向性测试样例生成和基于混合符号执行的测试例生成技术。基于细颗粒度污点分析的导向性测试例生成有效地降低了变异空间范围,提高了模糊测试的效率:作为导向性模糊测试的重要互补,基于混合符号执行的测试例生成技术能够对单条执行轨迹进行深度安全分析并生成高代码覆盖率的样本。此外,这两种样本生成技术都可以与校验和感知模糊测试技术相结合,提高模糊测试系统漏洞挖掘能力。
- 将整数溢出漏洞抽象为一个source-sink模型。在该模型指导下,提出程序脆弱性包络提取方法;进而通过静态符号执行技术遍历脆弱性包络,避免了对整个代码空间遍历,有效缓解了路径爆炸问题。
- 提出一种基于roBDD的污点分析方法,并实现了原型系统TaintReplayer。Taint Replayer采用离线污点分析模式,在对程序执行轨迹的重放过程中,采用roBDD描述污点属性,进行细颗粒度污点分析。实验结果表明,roBDD结构降低了污点分析对内存的需求,显著提高了污点分析的性能。
文末提出的展望
- 在未来工作中我们将重点研究如何更好的结合两类漏洞挖掘的方法,发挥两类挖掘技术各自优势、弥补两类技术的不足,实现灵活高效的动静结合的漏洞挖掘方法,并对已有挖掘系统进行整合和改进。进- -步,我们将研究构造健壮的、功能丰富的、可扩展性强的综合性漏洞挖掘研究平台,从基础设施层面为漏洞挖掘提供控制流分析、数据流分析、切片分析、代码插桩等支撑技术。
- 其他复杂漏洞模型分析与检测方法研究。
- 本文提出的路径爆炸缓解办法在大型程序上还没有较好的效果,未来,基于云计算平台并行化漏洞挖掘工作吸引了众多研究人员的高度关注。如何结合不同漏洞模型、设计并行化漏洞挖掘算法是本文未来工作的一个重点。
- 对抗策略下漏洞可利用性研究。面对地址随机化、数据执行保护等防护策略的广泛应用,如何自动化判定漏洞是否可以被利用,以及如何自动生成攻击样例,对攻防双方都有着重要的意义。在操作系统防护能力不断增强、攻击越来越困难的情况下,漏洞可利用性分析将成为下阶段的研究重点。
-
-
NEUZZ总结性分析
NEUZZ总结性分析
和大佬讨论了一下还做了汇总,需要整理一下想一想下一步该做些什么
程序平滑模型
创新性的使用了深度神经网络搭建程序平滑模型,解决了目前使用符号执行时面临的约束求解和梯度爆炸两个开放性难题的问题。
本文使用模型训练的目的是降低损失函数,即降低模拟输出与实际输出之间的距离。
梯度引导变异
梯度大的地方,可以认为其变异更容易产生路径的变化,变异方向与梯度的方向相同时,可以更可能的触发新的代码块覆盖。
源码实现细节
程序在进行变异的过程中,变异所基于的梯度是各个方向的梯度,即变异为从每次随机选择一个输出神经元开始,计算各个输如字节在该神经元上的梯度,然后根据排序,以2的各个次方的分组进行按组的变异。
一些问题
这个模型为什么需要afl的样本作为输入
模型的学习是较快的,但模型的增长是相对缓慢的,所以需要预先准备能达到一定覆盖率的样本。
模型的输出神经元个数是由什么决定的
模型的输出神经元是在变化的,因而采用参数axis=1的np.unique进行bitmap的整合,能将相关联的基本块整合到一起。由于程序中很多基本块之间的上下文关系都很紧密,所以将这些基本块合并,在接触到其中的区别的时候再分开,可以有效的降低模型训练的难度。因而如果想知道某一基本块是整合后的哪一个块需要用原bitmap进行比对。
增量学习的过程
由于某些代码块很显然是会同时出现的,这被称为多重共线性,会阻碍模型的收敛。因此本模型会仅考虑哪些至少激活了一次的边缘,并将其汇总在一起出现的边缘合并为一个边缘,0和0归类到一起,1和1归类到一起。
-
Keras使用
Keras 部分功能
这次算是与Keras和tensorflow打了一次交道了。。虽然最后并没有怎么用上。
自定义损失函数
损失函数的自定义用于实现一些目的的模型计算 。注意损失函数是模型训练的目的,而不属于模型之中。
def my_bin(y_true, y_pred): return K.binary_crossentropy(y_true,y_pred);这样的方式就可以重新写一个损失函数了。当然也是可以有额外的损失函数的参数的,就是需要去定义预设值
自定义层
这里给出官方的说明文档,最后没用上所以可没有具体的写
class MyLayer(Layer): def __init__(self, output_dim, **kwargs): self.output_dim = 1 super(MyLayer, self).__init__(**kwargs) def build(self, input_shape): assert isinstance(input_shape, list) # 为该层创建一个可训练的权重 self.kernel = self.add_weight(name='kernel', shape=(input_shape[0][1], self.output_dim), initializer='uniform', trainable=True) super(MyLayer, self).build(input_shape) # 一定要在最后调用它 def call(self, x): assert isinstance(x, list) a, b = x return [K.dot(a, self.kernel) + b, K.mean(b, axis=-1)] def compute_output_shape(self, input_shape): assert isinstance(input_shape, list) shape_a, shape_b = input_shape return [(shape_a[0], self.output_dim), shape_b[:-1]]官方文档的网址:https://keras.io/zh/layers/writing-your-own-keras-layers/,很多时候比个人写的blog有用的多
模型模拟
很有意思的想法,用一个新的模型根据之前的模型进行简化的模拟,然后可以对这个模型进行操作,也不会影响到之前的模型了。
还可以通过模型的predict来预测某个输入对应模型输出(当然是用model.predict([x])的方法也是可以的得到模型输出的,这两种得到的其实是一样的,就是新建立模型可以在上面做一些动作)。
dense1_layer_model = Model(inputs=model.input,outputs=model.get_layer('activation_2').output) dense1_output = dense1_layer_model.predict([x]) print dense1_output[0]关于计算模型梯度
loss = layer_list[-2][1].output[:,f]#分片,选择了第f个神经元的输出与输入之间的关系是个Tensor,shape(?,)。原先是shape(?,45)。 grads = K.gradients(loss,model.input)[0] iterate = K.function([model.input], [loss, grads]) loss_value, grads_value = iterate([x])最终得到的就是损失函数计算值和各输入字节的梯度
-
基于 roBDD 的细颗粒度动态污点分析
基于 roBDD 的细颗粒度动态污点分析
第一次接触污点分析,很多地方还不了解,就当是先入个门吧。目前先看看王铁磊大佬的文章跟着学一学
论文关注的研究现状
一个有代表性的方法是维护一个从内存地址到用于指示污染属性的数据结构的映射(即影子内存)。 许多传统的污染分析系统只关注内存地址是否被污染。 因此,布尔值足以存储内存单元格的 taint 属性。
通常,需要考虑两种依赖关系: 数据流依赖关系和控制流依赖关系]语句 S2是依赖于 S1 的控制流当且仅当 s 的执行被 sp. 有条件地保护。 语句 S2是依赖于 S1的数据流,当且仅当 S1 修改了 S2读取的资源并且在执行中优先于 S2。 在本文中,只关注数据流依赖性。
论文的主要工作
本文实现的污点分析技术,将实现变量对于所有输入位置的污点关系。
污点定义方式
如果z=x+y,x由输入0123决定,y由输入4567决定,则z由01234567决定对于n字节的整数,使用n个bool量来表示
二元决策图是一种用来表示布尔函数的数据结构。 BDD 有两个终端节点,即0端节点和 l 端节点。 除了两个终止节点外,其他节点(响应不同的 Booleanvariables)有两条边,称为0边和1边。 当 BDD 的变量顺序固定时,roBDD 给出了 BDD 的标准形式。 我们建议读者参阅参考资料。[11] B ryant R E . G rap h—b ased algorithm s f o r B oolean fun ction m an ipu lation . IE E E T ran s C om p ut. 19 8 6, 3 5 : 6 7 7- 6 9 l [12] B ryant R E . S ym b olic b oolean m anipulation w ith ord ered b in ary —d ecision d ia gram s. A C M C o m p ut Su rv, 19 92 , 2 4 : 2 9 3—3 18 。来具体的了解BDD(之后有需要再了解吧)
本文介绍了一种有效的离线细粒度污染分析系统 TaintReplayer。 TaintReplayer 主要由两个模块组成: 记录器和重播器。 有几个新颖的功能。 首先,TaintReplayer 是一个离线的污染分析系统。 它首先记录执行跟踪,然后重放跟踪。 在线污染分析的性能和内存开销往往导致目标程序不能很好地运行,甚至在程序运行的早期阶段就已经存在,而离线污染分析只能在运行时记录执行轨迹。 与在线污染分析相比,测井的性能开销大大降低 。 执行跟踪是可以接受的。 其次,在离线回放阶段,TaintReplayer 利用 obdds 表示集合结构,从而大大降低了内存使用量。 最后,TaintReplayer直接处理二进制程序,不需要访问源代码。 另外,TaintReplayer 可以在 Linux 和 windows 平台上运行。
本文的动态污点分析是基于二进制插桩技术。 记录器负责记录执行的痕迹。 对于每一条执行的指令,这些信息包括指令访问器的内存位置的地址和值,修改寄存器的值,以及指令的地址。 记录器还会记录一些有趣的系统调用的效果。 例如,对于将输入文件中的数据读入缓冲区的文件读取系统调用,记录的信息包括文件位置、缓冲区的起始地址和读取的字节数。
结果生成的是每个内存对于各个输入字节的依赖。(可以想见的这会非常庞大)使用roBDD来表示。
指令执行跟踪的处理
给定一个执行跟踪 T= <I, i0>,I 是执行指令的序列,i0是跟踪的第一条指令。 让 env 是一个 tuple (M,R) ,其中 M 是从内存地址到 roBDDs 的映射,而 R 是从寄存器到 roBDDs 的映射。 用 Fi表示指令 I 的语义功能,它负责根据指令 i 和输入环境的语义来更新 M 和 R。 开始的时候是M0 和 R0,
(Mi,Ri) = Fi * Fi-1 … F0(M0,R0)
指令语义函数 Fi 的目的是将污染信息从源操作数转移到目的操作数,特别是当系统调用指令系统并读取输入数据时,语义函数 f 将用唯一污染的 lacl 标记对应的内存地址。 下面的算法用于模拟系统读调用。
我们实现了一个 TaintReplayer 原型系统。 记录器模块构建在 PIN 二进制检测平台4的基础上,重播模块用 c + + 实现。 本文选择 BuDDY (一个 BDDpackage)作为roBDD 实现。
相比于别的动态污点分析工具,roBDD不会随输入的增加而大幅需要内存。结论为,ropdd 可以显著提高离线细粒度污点分析的性能,并且消耗更少的内存空间。
总结
提出了一种有效的离线细粒度污染分析方法,该方法首先记录执行轨迹,然后对执行轨迹(离线)进行污染分析,而不是在运行时(在线)跟踪输入数据的传播。 此外,我们的方法利用了减少排序的二进制决策图(roBDD)来表示集合结构。 实验结果表明,该方法能显著提高离线细粒度污染分析的性能。